# 旷视YOLOX算法介绍
论文地址:http://arxiv.org/abs/2107.08430 (opens new window)
代码:https://github.com/Megvii-BaseDetection/YOLOX (opens new window)
# 1.简介
2021年07月份,旷视的Zheng Ze与Sonttao Liu提交的论文中提出的Anchor Free检测算法。主要工作聚焦在a decoupled head和label assigment strategy SimOTA。作者使用YOLOX获得了2021年CVPR Autonomous Driving领域Streaming Perception Challenge的第一名BaseDet (opens new window)。
之前YOLO系列的论文自YoloV1后都是Anchor Based的,但自那之后如CornerNet/CenterNet/FCOS等Anchor Free的算法不断进步,YoloX的作者再次尝试将Anchor Free的算法技巧应用到Yolo算法上。作者认为YoloV4/YoloV5属于优化过度的Anchor Based算法,因此其提出的YoloX算法主要与YoloV3做比较。YoloX中的使用的baseline是YoloV3-SPP,YoloV3-SPP中作者引入了EMA权值更新,cosine lr schedule等策略。
# 2.YoloX所做的主要工作
# 2.1 分类/回归头解耦(Decoupled head)
在R-CNN系列目标检测论文中,bounding box位置回归和物体类别判断都是分两个输出头来做的,而Yolo系列论文使用的Yolo Head都是在同个向量中通过共同的神经网络同时输出回归和类别信息。如下图1,在YoloX中作者重新使用了Decoupled Head,通过实验证明了其能提升检测的效果,

- 1)加快收敛速度
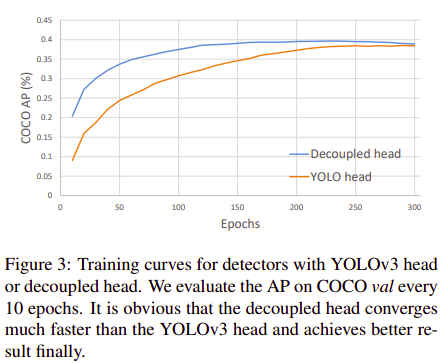
- 2)使用
NMS Free做End2End Yolo时性能下降小。
# 2.2 SimOTA
Label Assignment时目标检测中的关键点,以往多是基于Max IoU来实现Anchor Box正负标签的判定,属于基于先验知识的静态匹配方式,因一张图像中目标的数量是有限的,因此会将大量的Anchor判定为negative,造成严重的类别不平衡问题。ATSS (opens new window)提出了自适应训练样本采样算法,自适应确定判断Anchor正负标签的IoU阈值。Label Assignment问题是结合Ground Truth Boxes给每个Anchor Box分配类别,然后得到全局最优的结果,这个问题正好满足二分图优化的模型,因此也有不少工作是基于匈牙利算法 (opens new window),最优路经传输(Optimal transport assignment)来做的。OTA (opens new window)是YoloX作者2021年04月提交的论文中提出的方法,实现label的动态匹配。
advanced label assignment的四个要点
- 1)loss/quality aware
- 2)center prior
- 3)dynamic number of positive anchors
- 4) global view
YoloX作者指出通过Sinkhorn-Knopp算法求解OTA问题增加了约25%的训练时间,因此在YoloX中使用被称为SimOTA的dynamic top-K算法求近似解。
SimOTA算法流程:
- 1)先对每个
prediction-gt pair计算代价cost
- 2)对每个
top k个prediction作为positive sample,其余作为negative samples,超参数k对不同的ground truth box取不同的值,其选择见作者在OTA (opens new window)论文中的介绍和这篇博客 (opens new window)。
源码分析:
参考mmdetection中SimOTA的实现,见mmdet/core/bbox/assigners/sim_ota_assigner.py
graph TD
A(1.先调用get_in_gt_and_in_center_info方法) --> A1[1.1prior center是否落在gt bboxes中?]-->A2[1.2prior center是否落在gt box centers附近center_radius*stride_x/y矩形内?]-->B(2.初步判断priors哪些属于正样本is_in_gts_or_centers)-->C(3.bbox_overlaps将2的正样本与gt boxes分别计算IoU得iou_cost)
B-->D(4.binary_cross_entropy计算得cls_cost)
C-->E(5.cost_matrix:shape,num_posxgt_box_nums)
D-->E
E-->F(6.dynamic_k_matching得到每个positive_prior对应的gt_box)
F-->G(匹配完成)
class SimOTAAssigner(BaseAssigner):
def __init__(self,):
...
def _assign(self,
pred_scores,
priors,
decoded_bboxes,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None,
eps=1e-7):
"""Assign gt to priors using SimOTA.
Args:
pred_scores (Tensor): Classification scores of one image,
a 2D-Tensor with shape [num_priors, num_classes]
priors (Tensor): All priors of one image, a 2D-Tensor with shape
[num_priors, 4] in [cx, xy, stride_w, stride_y] format.
decoded_bboxes (Tensor): Predicted bboxes, a 2D-Tensor with shape
[num_priors, 4] in [tl_x, tl_y, br_x, br_y] format.
gt_bboxes (Tensor): Ground truth bboxes of one image, a 2D-Tensor
with shape [num_gts, 4] in [tl_x, tl_y, br_x, br_y] format.
gt_labels (Tensor): Ground truth labels of one image, a Tensor
with shape [num_gts].
gt_bboxes_ignore (Tensor, optional): Ground truth bboxes that are
labelled as `ignored`, e.g., crowd boxes in COCO.
eps (float): A value added to the denominator for numerical
stability. Default 1e-7.
Returns:
:obj:`AssignResult`: The assigned result.
"""
INF = 100000.0
num_gt = gt_bboxes.size(0)
num_bboxes = decoded_bboxes.size(0)
# assign 0 by default
assigned_gt_inds = decoded_bboxes.new_full((num_bboxes, ),
0,
dtype=torch.long)
valid_mask, is_in_boxes_and_center = self.get_in_gt_and_in_center_info(
priors, gt_bboxes)
valid_decoded_bbox = decoded_bboxes[valid_mask]
valid_pred_scores = pred_scores[valid_mask]
num_valid = valid_decoded_bbox.size(0)
if num_gt == 0 or num_bboxes == 0 or num_valid == 0:
# No ground truth or boxes, return empty assignment
max_overlaps = decoded_bboxes.new_zeros((num_bboxes, ))
if num_gt == 0:
# No truth, assign everything to background
assigned_gt_inds[:] = 0
if gt_labels is None:
assigned_labels = None
else:
assigned_labels = decoded_bboxes.new_full((num_bboxes, ),
-1,
dtype=torch.long)
return AssignResult(
num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
pairwise_ious = bbox_overlaps(valid_decoded_bbox, gt_bboxes)
iou_cost = -torch.log(pairwise_ious + eps)
gt_onehot_label = (
F.one_hot(gt_labels.to(torch.int64),
pred_scores.shape[-1]).float().unsqueeze(0).repeat(
num_valid, 1, 1))
valid_pred_scores = valid_pred_scores.unsqueeze(1).repeat(1, num_gt, 1)
cls_cost = (
F.binary_cross_entropy(
valid_pred_scores.to(dtype=torch.float32).sqrt_(),
gt_onehot_label,
reduction='none',
).sum(-1).to(dtype=valid_pred_scores.dtype))
cost_matrix = (
cls_cost * self.cls_weight + iou_cost * self.iou_weight +
(~is_in_boxes_and_center) * INF)
matched_pred_ious, matched_gt_inds = \
self.dynamic_k_matching(
cost_matrix, pairwise_ious, num_gt, valid_mask)
# convert to AssignResult format
assigned_gt_inds[valid_mask] = matched_gt_inds + 1
assigned_labels = assigned_gt_inds.new_full((num_bboxes, ), -1)
assigned_labels[valid_mask] = gt_labels[matched_gt_inds].long()
max_overlaps = assigned_gt_inds.new_full((num_bboxes, ),
-INF,
dtype=torch.float32)
max_overlaps[valid_mask] = matched_pred_ious
return AssignResult(
num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
def get_in_gt_and_in_center_info(self, priors, gt_bboxes):
num_gt = gt_bboxes.size(0)
repeated_x = priors[:, 0].unsqueeze(1).repeat(1, num_gt)
repeated_y = priors[:, 1].unsqueeze(1).repeat(1, num_gt)
repeated_stride_x = priors[:, 2].unsqueeze(1).repeat(1, num_gt)
repeated_stride_y = priors[:, 3].unsqueeze(1).repeat(1, num_gt)
# is prior centers in gt bboxes, shape: [n_prior, n_gt]
l_ = repeated_x - gt_bboxes[:, 0]
t_ = repeated_y - gt_bboxes[:, 1]
r_ = gt_bboxes[:, 2] - repeated_x
b_ = gt_bboxes[:, 3] - repeated_y
deltas = torch.stack([l_, t_, r_, b_], dim=1)
is_in_gts = deltas.min(dim=1).values > 0
is_in_gts_all = is_in_gts.sum(dim=1) > 0
# is prior centers in gt centers
gt_cxs = (gt_bboxes[:, 0] + gt_bboxes[:, 2]) / 2.0
gt_cys = (gt_bboxes[:, 1] + gt_bboxes[:, 3]) / 2.0
ct_box_l = gt_cxs - self.center_radius * repeated_stride_x
ct_box_t = gt_cys - self.center_radius * repeated_stride_y
ct_box_r = gt_cxs + self.center_radius * repeated_stride_x
ct_box_b = gt_cys + self.center_radius * repeated_stride_y
cl_ = repeated_x - ct_box_l
ct_ = repeated_y - ct_box_t
cr_ = ct_box_r - repeated_x
cb_ = ct_box_b - repeated_y
ct_deltas = torch.stack([cl_, ct_, cr_, cb_], dim=1)
is_in_cts = ct_deltas.min(dim=1).values > 0
is_in_cts_all = is_in_cts.sum(dim=1) > 0
# in boxes or in centers, shape: [num_priors]
is_in_gts_or_centers = is_in_gts_all | is_in_cts_all
# both in boxes and centers, shape: [num_fg, num_gt]
is_in_boxes_and_centers = (
is_in_gts[is_in_gts_or_centers, :]
& is_in_cts[is_in_gts_or_centers, :])
return is_in_gts_or_centers, is_in_boxes_and_centers
def dynamic_k_matching(self, cost, pairwise_ious, num_gt, valid_mask):
matching_matrix = torch.zeros_like(cost, dtype=torch.uint8)
# select candidate topk ious for dynamic-k calculation
candidate_topk = min(self.candidate_topk, pairwise_ious.size(0))
# topk_ious shape: candidate_topk x num_gts
topk_ious, _ = torch.topk(pairwise_ious, candidate_topk, dim=0)
# calculate dynamic k for each gt
# dynamic_ks shape: 1 x num_gts
# dynamic k正是基于最少`candidate_topk`个iou求和计算出来的,因此是dynamic的
# 每个 gt对应的topk是不一样的
dynamic_ks = torch.clamp(topk_ious.sum(0).int(), min=1)
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(
cost[:, gt_idx], k=dynamic_ks[gt_idx], largest=False)
matching_matrix[:, gt_idx][pos_idx] = 1
"""
以上生成的`matching_matrix`有可能1个`prior`对应多个`gt_boxes`,还需以下处理
从1个`prior`对应的多个`gt_boxes`选`cost`最小的那个作为`gt_box`
"""
del topk_ious, dynamic_ks, pos_idx
# prior_match_gt_mask shape like (num_priors,)
prior_match_gt_mask = matching_matrix.sum(1) > 1
if prior_match_gt_mask.sum() > 0:
cost_min, cost_argmin = torch.min(
cost[prior_match_gt_mask, :], dim=1)
matching_matrix[prior_match_gt_mask, :] *= 0
matching_matrix[prior_match_gt_mask, cost_argmin] = 1
# get foreground mask inside box and center prior
fg_mask_inboxes = matching_matrix.sum(1) > 0
valid_mask[valid_mask.clone()] = fg_mask_inboxes
matched_gt_inds = matching_matrix[fg_mask_inboxes, :].argmax(1)
matched_pred_ious = (matching_matrix *
pairwise_ious).sum(1)[fg_mask_inboxes]
return matched_pred_ious, matched_gt_inds
# 2.3 End2End Yolo(NMS Free)
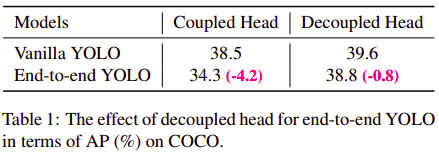
在2020年12月份,旷视的Jianfeng Wang等提交的论文End-to-End Object Detection with Fully Convolutional Network (opens new window)提出了不需要使用极大值抑制做后处理的检测方法,其改进了label assigment,将以往one2many的标签分配方式改成了one2one的方式,更多介绍可参考论文作者知乎上的文章 (opens new window)。2021年01月份阿里的Qiang Zhou等提交的论文[Object Detection Made Simpler by Eliminating Heuristic NMS](https://arxiv.org/abs/2101.11782)中也使用one2one的标签分配方式实现了NMS Free的目标检测算法,YoloX参考以上方法实现End2End训练得到如下表灰色的实验结果,可以看到对性能和准确率都有一定的影响:

最近聚焦在研究label assignment,因此这块NMS Free还没来得及看源码,先挖个坑。NMS Free其实也非常有意义,因为NMS存在,在边缘设备部署模型时,后处理部分不能像模型本身能放NPU上加速计算,故需在CPU上运算。
# 2.4 其他
数据增强方法
Mosaic:YoloV5作者在ultralytics-YOLOv3 (opens new window)中提出的MixUp(opens new window)2018年mixup: Beyond empirical risk minimization论文中提出,最早用于图像分类,自BoF(opens new window)后用于目标检测的数据增强

- Anchor Free: 做法类似于
FCOS(opens new window),每个feature map cell只预测一个输出框,相当于Anchor Number=1。同时为了得到更多的正样本,将Feature Map上cell落在目标中心附近一定范围的点都当作正样本,即Multiple Positive Sample。