# Position-Sensitive RoI Pooling
# 1.介绍
论文: Region-based Fully Convolutional Networks (opens new window)
代码: R-FCN (opens new window)
本论文作者同9.Deformable CNN (opens new window),是清华大学的代季峰 (opens new window)等于2016年05月份发表的。
这篇文章中作者提出了R-FCN,Region Based Fully Convolutional Network,2016年的时候对标的还是Region Based的Fast/Faster R-CNN算法。R-FCN是一种全卷积的网络结构,几乎所有的计算对于整张图像都是共享的,因此结果相比更为准确,计算更为高效。在这篇文章中作者提出了Position-Sensitive评分图以解决分类问题中对象的平移不变性和目标检测问题中的位置敏感性。
# 2.Position-Sensitive Score Map 和 Position-Sensitive RoI Pooling
R-FCN的整体架构:
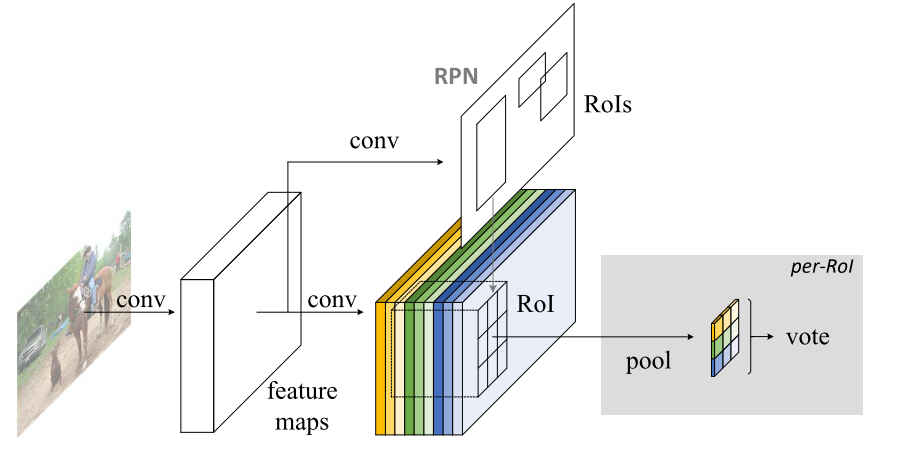
可以看到网络总体结构和Faster R-CNN (opens new window)十分相似,都是由RPN和RoI组成,明显的不同是图中Feature Maps被赋予了不同颜色,其被称之为Position-Sensitive Score Maps,具体含义如下面介绍。

如上图,Position-Sensitive Score Maps的通道数为C是检测对象的类别,+1表示的是背景类,RoI Pooling后得到的feature map的宽高,正如上图中所注释的,Position-Sensition Score Map上每个通道(一种颜色)所表示的是RoI所分的C+1类别的概率,这相当于把对象按部位拆成了human类别时,k=3在Position-Sensititve Score Maps中可以理解为:

在Position-Sensitive Score Map上做RoI Pooling时,输出feature map中的每一部分,分别取自Position-Sensitive Score Map的对应C+1个通道上,并非取自所有通道,在以上Position-Sensitive RoI Pooling图中用不同的颜色表示,因此Pooling后输出的feature map的大小为kxkx(C+1)。
将一个大小为RoI分成Position-Sensitive RoI Pooling的公式化表示为:
其中RoI Pooling的结果,Position-Sensative Score Map上通道n是RoI一个网格对应的Position-Sensative Score Map像素个数。
虽然网络结构中定义了这种操作,但是在网络训练时并没有进行有监督的训练,因此不禁让人怀疑最后网络的学习结果是否能反映出RoI不同部分的评分大小呢,在论文中作者给出了可视化的效果,说明了训练后Position-Sensitive RoI Pooling的有效性,图中右侧RoI Pool所得的结果中,评分越低颜色越深。

最后再补上,在2017年作者提出的Deformable RoI Pooling中 (opens new window)也对Position-Sensitive RoI Pooling做了改进。
# 3.源码解读
源码地址:Deformable-ConvNets/rfcn/operator_cxx/psroi_pooling.cu
/** 这里值得注意的是与论文上表述不同,代码实现中score map的channel不是pooled_width * pooled_height * (C+1)
* 而是 group_size * group_size * (C + 1)
* 而且score_map 特征图channel方向数据的平列方式是(C+1)x(group_size*group_size)而非,(group_size*group_size) x(C+1)
*/
template <typename DType>
__global__ void PSROIPoolForwardKernel(
const int count,
const DType* bottom_data,
const DType spatial_scale,
const int channels,
const int height, const int width,
const int pooled_height, const int pooled_width,
const DType* bottom_rois,
const int output_dim,
const int group_size,
DType* top_data,
DType* mapping_channel) {
CUDA_KERNEL_LOOP(index, count) {
// The output is in order (n, ctop, ph, pw)
int pw = index % pooled_width;
int ph = (index / pooled_width) % pooled_height;
int ctop = (index / pooled_width / pooled_height) % output_dim;
int n = index / pooled_width / pooled_height / output_dim;
// [start, end) interval for spatial sampling
const DType* offset_bottom_rois = bottom_rois + n * 5;
int roi_batch_ind = offset_bottom_rois[0];
DType roi_start_w = static_cast<DType>(round(offset_bottom_rois[1])) * spatial_scale;
DType roi_start_h = static_cast<DType>(round(offset_bottom_rois[2])) * spatial_scale;
DType roi_end_w = static_cast<DType>(round(offset_bottom_rois[3]) + 1.) * spatial_scale;
DType roi_end_h = static_cast<DType>(round(offset_bottom_rois[4]) + 1.) * spatial_scale;
// Force too small ROIs to be 1x1
DType roi_width = max(roi_end_w - roi_start_w, 0.1); //avoid 0
DType roi_height = max(roi_end_h - roi_start_h, 0.1);
// Compute w and h at bottom
DType bin_size_h = roi_height / static_cast<DType>(pooled_height);
DType bin_size_w = roi_width / static_cast<DType>(pooled_width);
int hstart = floor(static_cast<DType>(ph) * bin_size_h
+ roi_start_h);
int wstart = floor(static_cast<DType>(pw)* bin_size_w
+ roi_start_w);
int hend = ceil(static_cast<DType>(ph + 1) * bin_size_h
+ roi_start_h);
int wend = ceil(static_cast<DType>(pw + 1) * bin_size_w
+ roi_start_w);
// Add roi offsets and clip to input boundaries
hstart = min(max(hstart, 0), height);
hend = min(max(hend, 0), height);
wstart = min(max(wstart, 0),width);
wend = min(max(wend, 0), width);
bool is_empty = (hend <= hstart) || (wend <= wstart);
int gw = floor(static_cast<DType>(pw)* group_size / pooled_width);
int gh = floor(static_cast<DType>(ph)* group_size / pooled_height);
gw = min(max(gw, 0), group_size - 1);
gh = min(max(gh, 0), group_size - 1);
int c = (ctop*group_size + gh)*group_size + gw;
const DType* offset_bottom_data = bottom_data + (roi_batch_ind * channels + c) * height * width;
DType out_sum = 0;
for (int h = hstart; h < hend; ++h){
for (int w = wstart; w < wend; ++w){
int bottom_index = h*width + w;
out_sum += offset_bottom_data[bottom_index];
}
}
DType bin_area = (hend - hstart)*(wend - wstart);
top_data[index] = is_empty? (DType)0. : out_sum/bin_area;
mapping_channel[index] = c;
}
}