# Adaptive Training Sample Selection
# 1.简介
论文Bridging the Gap Between Anchor-based and Anchor-free Detection via
Adaptive Training Sample Selection (opens new window)
代码https://github.com/sfzhang15/ATSS (opens new window)
ATSS是中科院自动化研究所的Shifeng Zhang等最早于2019年12月份提交的论文中提出的方法,发表在CVPR2020会议上。
文中分析了Anchor Based和Anchor Free的检测方法,性能差异的主要原因在于正负训练样本的定义方式不同,而和回归目标是基于**点式(point)还是盒式(box)**关系不大。Anchor Free检测常用的有两种方法,一种是keypoint_based,另一种是center_based。keypoint_based的Anchor Free目标检测算法同标准的keypoint estimation pipeline,和anchor based的目标检测算法差异较大。但center_based的Anchor Free目标检测算法与Anchor Based的方法比较相近,center_based方法将point作为预设样本(如FCOS),Anchor Based方法是将anchor作为预设样本(如RetinaNet)。Anchor Based的RetinatNet与Center Based的FCOS的主要区别是:
- 1)
feature map中每个位置的anchor数量不同,RetinaNet每个点生成多个anchor boxes,FCOS每个点生成一个anchor point - 2)正负样本的定义方式不同,
RetinaNet使用IoU来判定正负样本,FCOS使用patial and scale constraints来判断。 - 3)回归起始状态不同。
RetinaNet是基于Anchor Box的FCOS是基于Anchor Point的
ATSS分析了Anchor Based和Anchor Free检测算法实现上的差异,得出的结论是正负样本定义方式的不同影响了两种方法检测效果的差异。基于此论文提出了Adaptive Training Sample Selection(ATSS)算法以基于目标特征自动的计算正负样本。本文还基于实验得出了在同个位置没必要使用多个anchor box做检测的结论。
# 2.目标检测相关
graph LR
A(ObjectDetector)-->B(AnchorBased)
A-->C(AnchorFree)
B-->B1(OneStage:SSD)
B1-->B11(fusing context information from different layers)
B1-->B12(training from scratch)
B1-->B13(introducing new loss function)
B1-->B14(anchor refinement and matching)
B1-->B15(architecture redesign)
B1-->B16(feature enrichment and alignment)
B-->B2(TwoStage:FasterR-CNN)
B2-->B21(architecture redesign and reform)
B2-->B22(context and attention mechanism)
B2-->B23(multiscale training and testing)
B2-->B24(training strategy and loss function)
B2-->B25(feature fusion and enhancement)
B2-->B26(better proposal and balance)
C-->C1(KeyPointBased:CornerNet/GridR-CNN/ExtremeNet/CenterNet/RepPoints)
C-->C2(CenterBased:YOLO/DenseBox/FCOS/CSP/FoveaBox)
# 3.Anchor Based与Anchor Free目标检测算法的差异分析
Anchor Based选择RetinaNet作为代表,Anchor Free选择FCOS作为代表,从以下三方面进行分析:
- 1)正负样本定义
- 2)初始回归状态,是回归
- 3)每个位置的
anchor数量
# 3.1 RetinaNet与FCOS的对比
设置RetinaNet的Anchor box数量为1。对FCOS的改进:
- 1)将
centernerss移到regression分支 - 2)使用
GIoU Loss - 3)将回归目标使用对应level的stride来归一化
这些提升了FCOS的检测效果,coco minival上的map从37.1提升到了37.8,进一步拉开了Anchor=1的RetinaNet与FCOS的差距。
FCOS中使用的一些trick在Anchor=1的RetinaNet中也能使用,如检测头中使用的Group Normlization, GIoU,限制ground truth box中的正样本,对特征金字塔的每层加上一个中心度分支和可训练参数。将这些trick逐一加到RetinaNet上的对比结果为:
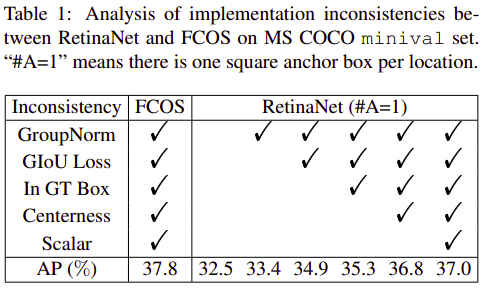
从上图可以看出,将所有的通用trick都应用到RetinaNet上后,MAP依然有0.8的差距。除了以上指出的通用性差异后,还有两点不同,一个是正负样本的定义方式,另一个是回归任务本身,RetinaNet是基于Anchor Box回归,FCOS是基于Anchor Point回归。
# 3.1 正负样本定义的区别
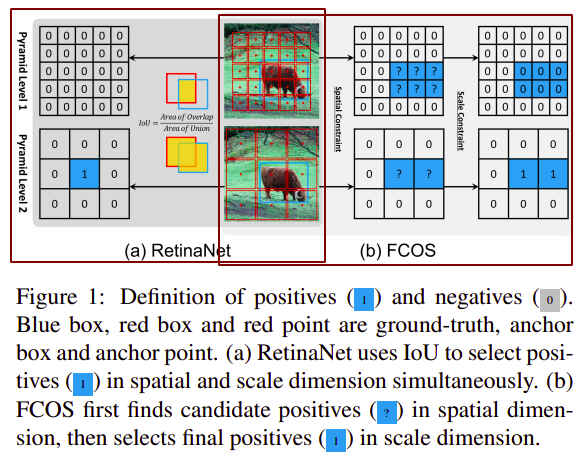
如上图,RetinaNet根据ground truth box与anchor box之间的IoU的值来判断是正样本还是负样本,通常设置两个超参数Anchor Box被忽略,不参与训练,RPN生产的Proposal Box基于FPN论文中提出的方程式2赋值给某个feature层 (opens new window)。FCOS则先根据Anchor Point的空间位置是否落在ground truth box中找出可能为正的Anchor Point,再根据Anchor Point对应feature map上的回归范围regression scale来近一步确认是否为正样本,参考见博客FCOSNet (opens new window)。基于Spatial and Scale的正样本判定方式决定了检测器的优秀性能,如下表,使用Spatial and Scale后,Anchor=1的RetinaNet的MAP也提升到了37.8,换用IoU的FCOS的MAP降到了36.9:

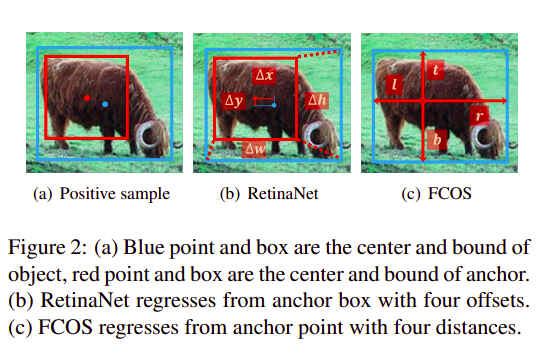
# 3.2 回归起始位置的差异
如下图,Anchor=1的RetinaNet回归的是AnchorBox相对于ground truth box的平移缩放box的回归,而FCOS回归的是中心点距离ground truth box四边的距离box或point的回归方式对最终的结果影响不大,37->36.9,‵37.8->37.8`。
综合3.1和3.2的分析,可以得出结论:是正负样本的定义方式不同影响了Anchor Based和Anchor Free算法的性能。
# 4.自适应训练样本选择
从前面作者得出的结论,How to define positive and negative samples极大影响了检测器的性能,基于此作者提出了新的samples分类算法,自适应训练样本选择(Adaptive Training Sample Selection, ATSS)。
Anchor Based基于IoU和Anchor Free基于Scale Range的正样本定义方法都依赖预先定义好的超参数,ATSS提出了一种自适应取阈值的方法,减少了sample definition所需的超参数。

以一张输入图像为例说明上图ATSS算法的工作流程:
- 1)对于1个
ground truth box,分别在每个金字塔特征层上取中心anchor boxes作为候选positive sample,对于有candidate positive anchor boxes - 2)计算
candidates与ground truth boxesIoU - 3)计算2)中
IoU的均值 - 4)取
positive,其余的Anchor Boxes都是negative
作者指出,当一个anchor box同时落入两个ground truth box中时,会将其分配给IoU比较大的ground truth box。

从上图可以看出ATSS的作用,对于某个ground truth box,图a中标准差较大,意味着有某个金字塔特征层比较适合预测该box,因此阈值box,因此选取的阈值
作者还指出使用ATSS,可以使得对于不同大小的目标对象得到相同比例的正负训练样本。对于标准正态分布有16%的样本落在IoU of candidates不是正态分布,正样本的比例依然保持在了20% of RetinaNet和FCOS都会倾向于对大目标生成更多的正样本。
ATSS使用的超参数很少,只有k一个,且算法效果对k不敏感。实验证明k取[3, 5, 7, 9, 11, 13, 15, 17, 19]时map变化不大:

# 5.代码实现
mmdetection中ATSS算法的实现在ATSSAssigner类中,assign的部分代码如下:
# Selecting candidates based on the center distance
candidate_idxs = []
start_idx = 0
for level, bboxes_per_level in enumerate(num_level_bboxes):
# on each pyramid level, for each gt,
# select k bbox whose center are closest to the gt center
end_idx = start_idx + bboxes_per_level
distances_per_level = distances[start_idx:end_idx, :]
selectable_k = min(self.topk, bboxes_per_level)
_, topk_idxs_per_level = distances_per_level.topk(
selectable_k, dim=0, largest=False)
candidate_idxs.append(topk_idxs_per_level + start_idx)
start_idx = end_idx
candidate_idxs = torch.cat(candidate_idxs, dim=0)
# get corresponding iou for the these candidates, and compute the
# mean and std, set mean + std as the iou threshold
candidate_overlaps = overlaps[candidate_idxs, torch.arange(num_gt)]
overlaps_mean_per_gt = candidate_overlaps.mean(0)
overlaps_std_per_gt = candidate_overlaps.std(0)
overlaps_thr_per_gt = overlaps_mean_per_gt + overlaps_std_per_gt
is_pos = candidate_overlaps >= overlaps_thr_per_gt[None, :]
# limit the positive sample's center in gt
for gt_idx in range(num_gt):
candidate_idxs[:, gt_idx] += gt_idx * num_bboxes
ep_bboxes_cx = bboxes_cx.view(1, -1).expand(
num_gt, num_bboxes).contiguous().view(-1)
ep_bboxes_cy = bboxes_cy.view(1, -1).expand(
num_gt, num_bboxes).contiguous().view(-1)
candidate_idxs = candidate_idxs.view(-1)
# calculate the left, top, right, bottom distance between positive
# bbox center and gt side
l_ = ep_bboxes_cx[candidate_idxs].view(-1, num_gt) - gt_bboxes[:, 0]
t_ = ep_bboxes_cy[candidate_idxs].view(-1, num_gt) - gt_bboxes[:, 1]
r_ = gt_bboxes[:, 2] - ep_bboxes_cx[candidate_idxs].view(-1, num_gt)
b_ = gt_bboxes[:, 3] - ep_bboxes_cy[candidate_idxs].view(-1, num_gt)
is_in_gts = torch.stack([l_, t_, r_, b_], dim=1).min(dim=1)[0] > 0.01
is_pos = is_pos & is_in_gts