# Cityscapes数据集简介
# 1.简介
Daimler AG现在称为Mercedes-Benz研发中心和达姆施塔特工业大学(德语:Technische Universität Darmstadt)研究人员开放的数据集,论文发表在2016年的CVPR。cityscapess采集自德国及附近国家的50个城市,包括了春夏秋三个季节的街区场景,且使用双目相机的获取了立体视觉视频序列。研究人员认为雨雪等极端天气需要特殊的处理方法和数据集进行研究,因此在cityscapess数据集中没有采集此类数据。数据采集使用的是1/3英寸 CMOS 2MP sensors (OnSemi安森美
AR0331),帧率为17的卷帘相机,包括左目和右目,基线距离22cm,采集的是色彩深度为16位的的HDR图像。
数据集有选自27个城市的5000张图像进行了pixel-level像素级的语义和实例标注,可用于训练语义分割网络,这5000张中的每一张都取自于对应的一个包含30帧的视频序列的第20帧,剩余23个城市的20000张图像进行了粗略标注,这20000张图像是每间隔20s或汽车行驶20m采集一张得到的。精标一张数据平均1.5h,粗标一张数据7min。不同的标注人员对选出来的30张数据进行重复标注,像素一致性达96%,去除可标注为unclear的类别后,像素一致性达98%。
分割数据集包含了33个类,因部分类别数据量过于稀少,在验证数据集上,只有19个语义分割类,因此要根据*_polygons.json文件生成*_labelTrainIds.png用以训练语义分割网络,可借助cityscapesScripts工程中的cityscapesscripts/preparation/createTrainIdLabelImgs.py脚本,在语义分割的5000张图像的标注文件中,转换后训练时设置成ignore_indexe的类别255的像素个数分布为max: 1105427.0, min: 114462.0, avg: 263878.772,图像大小是2048x1024,255的占比最高大于50%。有个问题就是,使用语义分割模型测试输入一张图像,其输出每个像素的类别,这些类别都在0-18上,是无法预测出255这种类别的,对于在标签文件上本来属于255类别的像素也会被预测成0-18,这是否会影响模型的推理输出呢?
语义分割数据集以城市为单位划分,分成了train:2975张,validation:500张,test:1525张,
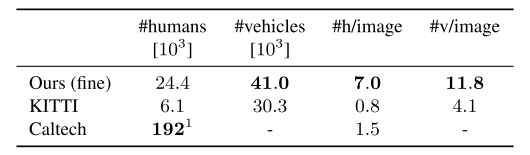
与KITTI/CamVid/DUS数据集进行对比,
- 更多的交通参与实例(汽车和人)
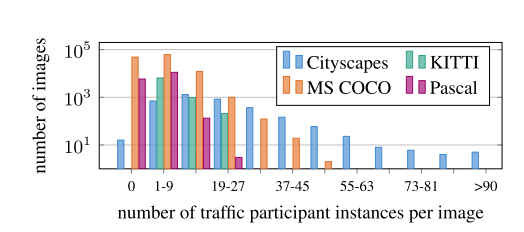
human和vehicle数量分布,与Caltech和KITTI对比
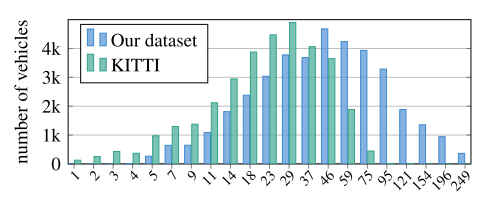
- 立体信息,汽车到相机距离的分布
# 目录结构
示例:
.
├── gtBbox3d
│ ├── test
│ │ ├── berlin
│ │ ├── bielefeld
│ │ ├── bonn
│ │ ├── leverkusen
│ │ ├── mainz
│ │ └── munich
│ ├── train
│ │ ├── aachen
│ │ ├── bochum
│ │ ├── bremen
│ │ ├── cologne
│ │ ├── darmstadt
│ │ ├── dusseldorf
│ │ ├── erfurt
│ │ ├── hamburg
│ │ ├── hanover
│ │ ├── jena
│ │ ├── krefeld
│ │ ├── monchengladbach
│ │ ├── strasbourg
│ │ ├── stuttgart
│ │ ├── tubingen
│ │ ├── ulm
│ │ ├── weimar
│ │ └── zurich
│ └── val
│ ├── frankfurt
│ ├── lindau
│ └── munster
├── gtFine
│ ├── test
│ │ ├── berlin
│ │ ├── bielefeld
│ │ ├── bonn
│ │ ├── leverkusen
│ │ ├── mainz
│ │ └── munich
│ ├── train
│ │ ├── aachen
│ │ ├── bochum
│ │ ├── bremen
│ │ ├── cologne
│ │ ├── darmstadt
│ │ ├── dusseldorf
│ │ ├── erfurt
│ │ ├── hamburg
│ │ ├── hanover
│ │ ├── jena
│ │ ├── krefeld
│ │ ├── monchengladbach
│ │ ├── strasbourg
│ │ ├── stuttgart
│ │ ├── tubingen
│ │ ├── ulm
│ │ ├── weimar
│ │ └── zurich
│ └── val
│ ├── frankfurt
│ ├── lindau
│ └── munster
├── leftImg8bit
│ ├── test
│ │ ├── berlin
│ │ ├── bielefeld
│ │ ├── bonn
│ │ ├── leverkusen
│ │ ├── mainz
│ │ └── munich
│ ├── train
│ │ ├── aachen
│ │ ├── bochum
│ │ ├── bremen
│ │ ├── cologne
│ │ ├── darmstadt
│ │ ├── dusseldorf
│ │ ├── erfurt
│ │ ├── hamburg
│ │ ├── hanover
│ │ ├── jena
│ │ ├── krefeld
│ │ ├── monchengladbach
│ │ ├── strasbourg
│ │ ├── stuttgart
│ │ ├── tubingen
│ │ ├── ulm
│ │ ├── weimar
│ │ └── zurich
│ └── val
│ ├── frankfurt
│ ├── lindau
│ └── munster
路径:{root}/{type}{video}/{split}/{city}/{city}_{seq:0>6}_{frame:0>6}_{type}{ext}
参数解读:
{root},数据集根路径,安装使用cityscapesScripts提供的工具csViewer和csLabelTool等时,需先设置export CITYSCAPES_DATASET={root}type,数据的类型,如gtFine精准标注的分割数据,leftImg8bit左目LDR图像等split,可能的值有train/val/test/train_extra/demoVideo等,有些可能时空的city,采集数据的城市seq,图像数据所在视频序列编码,6位数字frame,图像所在视频帧的编码,6位数字ext,文件扩展名,如标注的json文件_polygons.json,全景分割中使用的实例标签文件instanceIds.png等
以上路径中的type可选的值有:
gtFine,精准标注的5000张数据的标注文件,同样划分成train/val/test,对于每个图像对应的标注文件有以下几个:
aachen_000085_000019_gtFine_color.png
aachen_000085_000019_gtFine_instanceIds.png
aachen_000085_000019_gtFine_labelIds.png
aachen_000085_000019_gtFine_polygons.json
_gtFine_polygons.json,标注生成的json文件,可用来生成_instanceTrainIds.png和_labelTrainIds.png_labelIds.png,以labelId展示的语义分割标签文件,_instanceIds.png,以labelId展示的实例分割标签文件_color.png,可视化文件
在使用gtFine中的数据做语义分割和实例分割模型训练时,需将标注文件转成19个类的TrainIds上,可以借助cityscapesScripts中的csCreateTrainIdLabelImgs和csCreateTrainIdInstanceImgs工具生成以下图像:
aachen_000085_000019_gtFine_instanceTrainIds.png
aachen_000085_000019_gtFine_labelTrainIds.png
gtCoarse,粗略标注的19998张图像leftImg8bit,左目8位LDR图像rightImg8bit右目8位LDR图像gtBbox3d,2020年7月发布的3d 汽车检测的标注文件,对精准标注的5000张图像标注了汽车的3d检测框,可见论文Cityscapes 3D (Gählert et al., CVPRW '20) (opens new window)gtBboxCityPersons,17年发布的行人检测标注文件
cityscapesScripts中提供的工具主要有:
csViewer,可视化图像,及对应的标注文件,可调整透明度csLabelTool,数据集使用的标注文件csCreateTrainIdLabelImgs,根据_polygons.json生成labels.py中定义的TrainIds语义分割标签图像csCreateTrainIdInstanceImgs,根据_polygons.json生成labels.py(opens new window)中定义的TrainIds标签实例分割图像
详细的可以在cityscapesScripts (opens new window)中找到.
总结一下,这个2015年公开的数据集,到现在可以支持验证的任务有:
- 语义分割
- 实例分割
- 全景语义分割
- 3D 物体检测(汽车)
- 行人检测
其有左目右目的数据和视差图,应该可以用来做单目深度估计网络的训练.
# 参考资料
1.https://www.cityscapes-dataset.com/dataset-overview/ (opens new window)
2.https://github.com/mcordts/cityscapesScripts (opens new window)