# Transformer 介绍
# 1.基础介绍
这是Google2017年06月份发表的文章,在这篇文章中作者提出了后来对CV和NLP都产生了影响很大的Transformer网络结构,成为继MLP和RNN后又一倍受关注的基础模型。用于序列化数据的学习以输出序列化的预测结果,如应用在NLP领域。Transformer最早的提出就是应用在机器翻译领域,在WMT2014 英语翻译成德语的任务上,BLEU指标达到了28.4,比之前的SOTA提升了2个点。Transformer中使用多头注意力层替换了之前序列转录模型中使用循环神经网络单元。
图片来自于1 (opens new window)
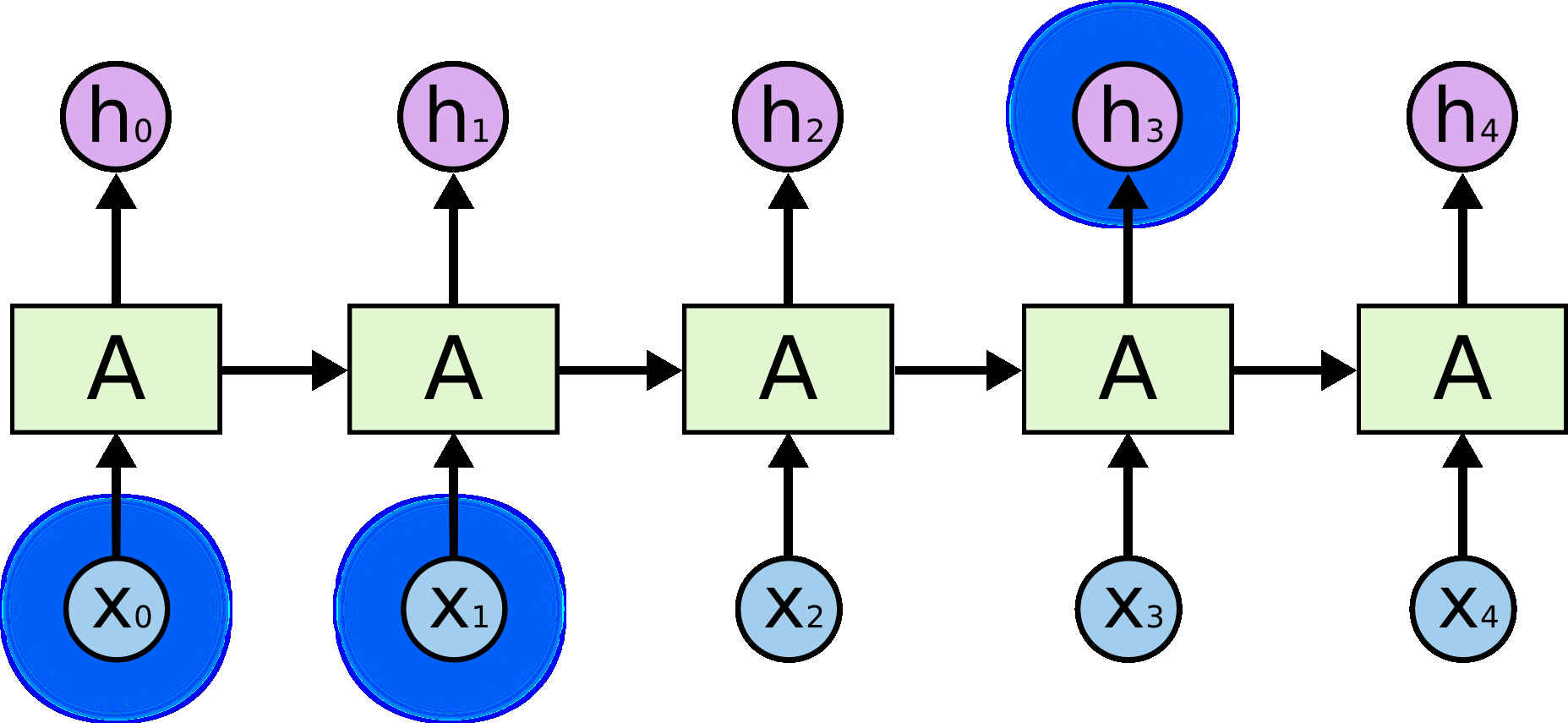
在RNN中,如上图,要计算Transformer结构使用自注意力机制,使得模型能够进行并行化计算,提升训练速度。
# 2.网络结构
对于序列数据的学习,经典的结构就是编码-解码结构,编码器将输入序列Transformer也是编码解码结构,其中编码解码模型都是由自注意力层和全连接层组成。其网络结构如下图:
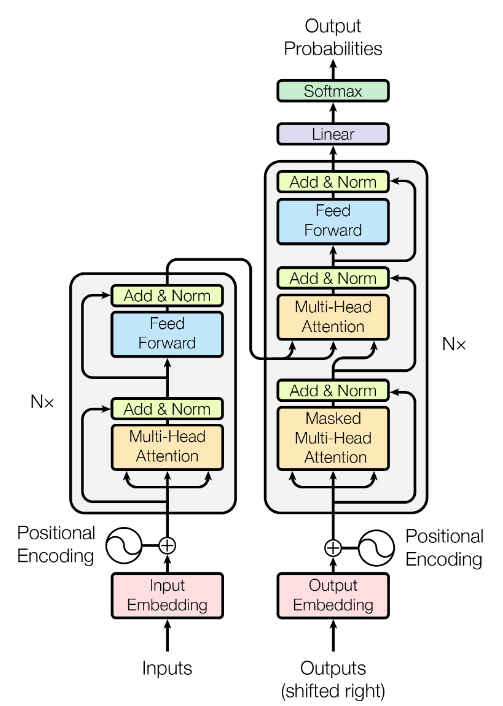
如上图,编码器中的一个block由两个子层sublayer组成,分别是MultiHead Attension层和MLP层组成。MLP层中使用了残差结构,并使用了Layer Normalization,表示为
解码器中除了使用了于编码器中相同的两个子层外还引入了第三种子层Masked Multi-Head Attention层用于模型自回归的学习,保证在模型训练时t时刻不会看到
下面对上图中的各个组成单元分别进行介绍:
# 2.1 Input/Output Embedding
Embedding这个词字面意思表示嵌入,这里介绍,Embedding是将高维数据转换成低维数据 (opens new window),借此可将字词的稀疏向量进行向量化表示。常见的Embedding由自然语言处理中的word embedding,图神经网络中的node embedding等。在这篇文章中作者介绍了NLP中的Word Embedding (opens new window)。
# 2.2 自注意力机制 self-attention
注意力函数可以看成是query值和key-value对到输出output的一个映射,query/key/value都是向量,output和value维度相同,output是value的加权和,每个value的权重通过计算query和key的相似度得到的,相似度的计算也被称为compatibility function,不同的注意力机制有不同的计算方法。
transformer中使用的query和key是等长的,维度都为output和value的维度是transformer中使用的query和key的相似度计算方式很简单,就是计算两个向量的内积再除以向量的维度,然后做softmax得到权重值。
实际计算中,会将多个query/key/value向量打包计算,写成矩阵的形式为:
这里因为有除以scaled dot product attention。之所以除以query和key之间的相似度,减少尺度导致的误差变化。
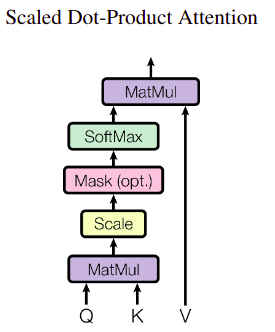
多头注意力机制 Multi-Head Attention
将前面介绍的attention中的query/key/value通过可学习参数的线性变换投影h次,得到h个query/key/value函数,将每个函数的输出并到一起再经过线性投影得到最终的输出。

计算公式为:
其中,
从网络结构图中可以看到,在编码器中的注意力层和解码器的第一个注意力层,Q/K/V使用的是同一个输入,因此这种注意力机制被称为自注意力机制。
# 2.3 point-wise全连接层
普通的全连接层,其输入的shape:[N,C]其中,N表示的是样本的数量,C表示每个特征的维度,而point_wise全连接层的输入shape:[N,L,C]其中N表示的是样本的数量,L表示句子的长度,C表示的是单词的个数,然后每次全连接是作用在最后一个维度C上的。
pytorch中的nn.Linear函数在处理3dtensor时默认是作用在最后一维上的,可以写成下面形式:
fc = nn.Sequential(
nn.Linear(512, 12),
nn.ReLU(),
nn.Linear(12, 28),
)
t = torch.randn((3, 16, 512))
fc(t).shape
# torch.Size([3, 16, 28])
计算公式如下:
# 2.4 位置编码 Position Encoding
前面介绍的attention中只是使用query/key的形式将输出表示成了value的加权和,这里没有输入序列的顺序信息,在RNN中是通过逐个词输出来学习序列信息的,而transformer中是将一个序列一次性输入到模型中,并没有序列中每个单词的信息,因此,这里引入位置编码来表示输入序列的时序信息,并将其作为模型的输入。
对于长度为L的输入序列,要标识每个单词的位置信息,一种方式是给每个位置生成一个唯一的表示位置的向量。transformer中使用如下的方式来计算输入序列的位置编码:
其中,Input Embedding后得到的每个词的维度相同。
使用pytorch实现的位置编码函数为:
import torch
def position_encoding(
seq_len: int, dim_model: int, device: torch.device = torch.device("cpu"),
) -> Tensor:
pos = torch.arange(seq_len, dtype=torch.float, device=device).reshape(1, -1, 1)
dim = torch.arange(dim_model, dtype=torch.float, device=device).reshape(1, 1, -1)
phase = pos / 1e4 ** (dim // dim_model)
return torch.where(dim.long() % 2 == 0, torch.sin(phase), torch.cos(phase))
从上面的代码可以看到,Position Encoding没有使用需要学习的参数,只是手动设计了表示序列位置信息的编码方式。
# 3.输入处理过程示例
以transformer用于翻译任务为例:
输入: x = I am cold
输出: y = 我冷
输入句子的dictionary中有3个词,则输入可以表示成:
word2index = {"I":0,"am":1,"cold":2}
输入句子的向量表示为:
x = [[[0],[1],[2]]
transformer中输入的处理主要有input embedding和position encoding这两步,如下图:
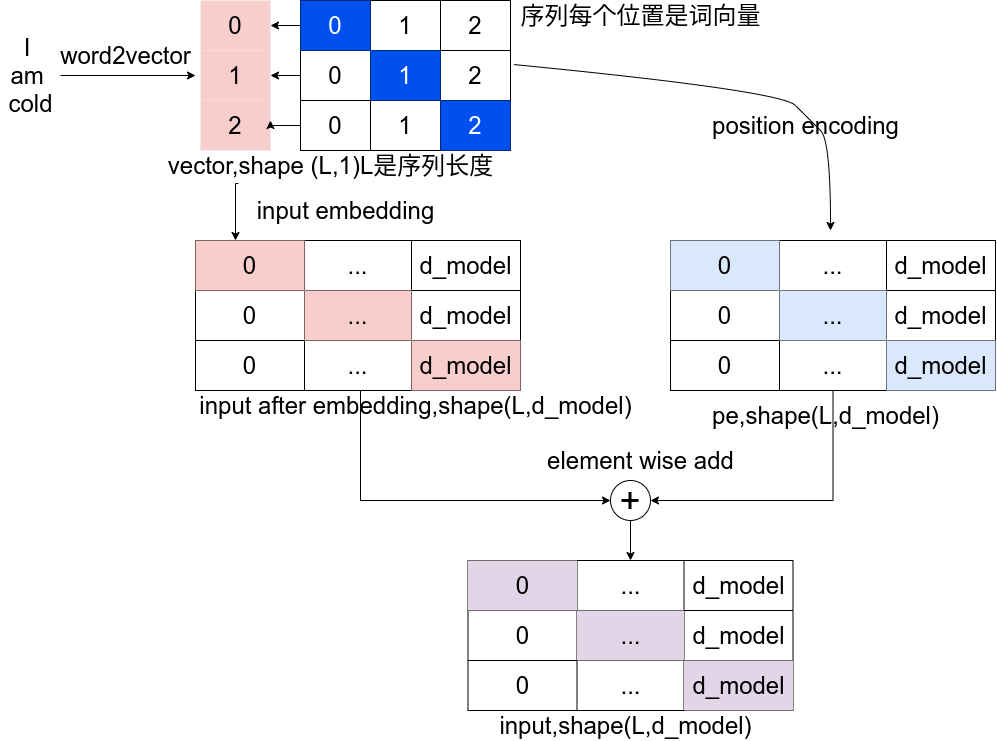
对输入句子序列处理结束后将其输入到attention中进行处理,其处理过程如下图所示:

上图中attention中使用的权重的维度,Single Head的计算过程,对于Multi Head,使用多组concatenate即可。
上图描述了attention的计算过程,在attention之后的计算是point wise feed forward。其计算过程表示如下图:
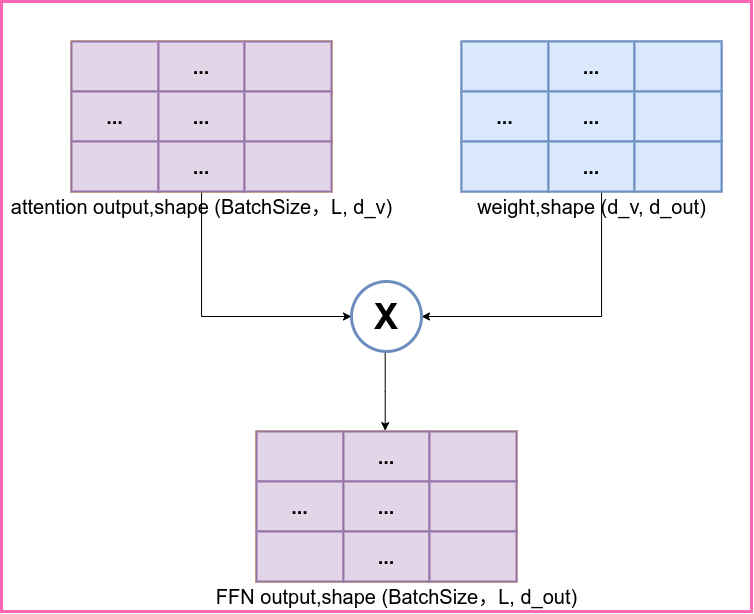
可以看到这里的FFN是作用在输入样本序列的每个单词向量上的,与之前常见的FFN作用在整个样本上不同。
pytorch中的nn.Linear层处理3d向量时,默认作用在最后一维进行计算,因此可以将attention层输出的结果直接输入到nn.Linear中。
fc = nn.Sequential(
nn.Linear(512, 12)
)
t = torch.randn((3, 16, 512))
fc(t).shape
# torch.Size([3, 16, 12])
# 4.代码实现
使用pytorch实现的transformer可以将代码仓库 (opens new window)。