# Focal Loss
# 1.基础介绍
这篇论文是HeKaiMing团队,2017年08月提交的,聚焦于探讨一阶段目标检测器与二阶段目标检测器的性能差异,**作者发现一阶目标检测的方法准确率不如二阶段目标检测器的主要原因是正负anchor训练样本的极度不平衡,一阶检测头给出的上万个候选框中大部分不包含物体,正负数据比列可达
什么意思呢?负样本数量太大,占总的loss的大部分,而且多是容易分类的,因此使得模型的优化方向更倾向于发现负样本,以前的算法使用OHEM算法来应对这种情况,Online Hard Example Mining,OHEM 每个batch中只取损失值最高的n个样本参与训练,OHEM算法虽然增加了错分类样本的权重,但是OHEM算法忽略了容易分类的样本。
Focal Loss 可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。
# 2.Focal Loss
# 2.1常规二分类交叉熵
也可以写成:
# 2.2 Focal Loss解读
上面普通的Binary Cross Entropy,BCE等同的对待每个类别的样本,无法处理类别不平衡的情况。
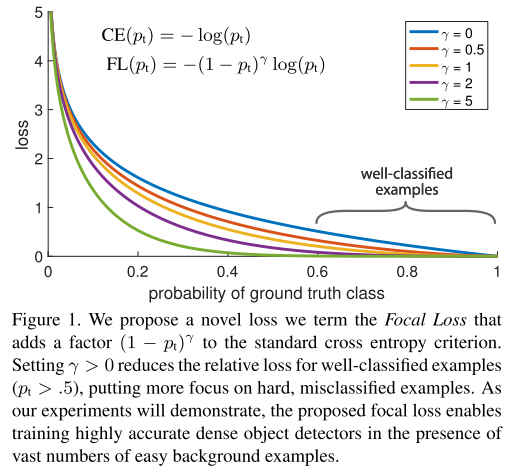
Focal Loss主要是引入了类别权重系数和简单/困难学习样本调节因子实现了对二分类类别不平衡样本数据的学习.
先写出Focal Loss的公式:
在论文中模型RetinaNet使用Focal Loss设置的
如上图,当Focal Loss就退化成了普通的BCE损失。
# 3.源码实现
import numpy as np
def focal_loss(preds: np.array, target: np.array):
alpha = 0.25
gamma = 2
alpha_t = alpha * target + (1 - alpha) * (1 - target)
p_t = (1 - preds) * target + preds * (1 - target)
focal_loss = -alpha_t*p_t.pow(gamma) * [target*np.log(preds)+(1-target) * log(1 - preds)]
return focal_loss