# 神经网络参数优化
# 1.背景介绍
反向传播算法是深度学习的基石,在2017年有一段时间总会跟着CS231N的课程讲义反复推导神经网络中
反向传播,时至今日再重新回顾一下神经网络中的优化方法。
# 2.神经网络的模型
对于线性分类器:x.shape为(N,D),N表示的是样本数目,D是X的特征维度,s.shape为(N,K),K表示类别的数目,s即是每个样本对应每个类别的评分。
全连接神经网络是有很多个线性分类器组成的,如带一个隐层的2层全连接网络W1.shape为(D,H),其中H表示的W2.shape为(H,K)。max函数是引入的作用在向量中每个元素上的非线性单元函数,如果没有max,则s=WX,其中
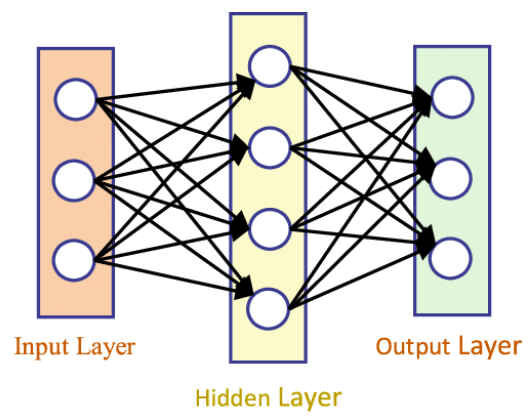
单个神经元来分析,类比与生物学中神经细胞,有树突,轴突等组成,神经网络神经元由参数W和非线性激活函数组成,如下图:
上图中右侧神经元表示,输入的数据为3维sigmoid,带1个隐含层的全连接神经网络就具备了拟合任何连续函数的能力。
# 3.神经网络中的参数更新初探
一个机器学习分类算法的核心由三大块组成,一个是评分函数score function将原始像素图像映射成类别评分;一个是损失函数loss function,用来评估预测结果与标签的一致程度,预测结果越准确loss越低,预测结果越不准,loss越高。另外一部分就是score function的参数更新即机器学习算法的优化问题,找到一组最优的参数loss的值尽量低。如最简单的线性分类器SOFTMAX+CrossEntropy:
理解了神经网络后,要完成神经网络的训练还需要知道神经网络的参数是如何更新的。
先生成实验样本数据:
from matplotlib import pyplot as plt
import numpy as np
N = 100 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N*K,D)) # data matrix (each row = single example)
y = np.zeros(N*K, dtype='uint8') # class labels
for j in range(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # radius
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
# lets visualize the data:
plt.scatter(X[:, 0], X[:, 1], c=y, marker='o', s=20)
plt.show()
# 3.1随机查找取最优
一个头脑风暴想法是随机选取W/b多次,然后取结果最好的那次权重:
last_loss = float('inf')
W = None
b = None
for i in range(10000):
Wt = 0.015 * np.random.randn(D,K)
bt = np.random.randn(1,K)
scores = np.dot(X, Wt) + bt
num_examples = X.shape[0]
# get unnormalized probabilities
exp_scores = np.exp(scores)
# normalize them for each example
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
correct_logprobs = -np.log(probs[range(num_examples),y])
# compute the loss: average cross-entropy loss and regularization
data_loss = np.sum(correct_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(Wt*Wt)
loss = data_loss + reg_loss
if loss < last_loss:
last_loss = loss
W = Wt.copy()
b = bt.copy()
print(f"step: {i} loss: {loss} min loss: {last_loss}")
# evaluate training set accuracy
scores = np.dot(X, W) + b
predicted_class = np.argmax(scores, axis=1)
print('training accuracy: %.2f' % (np.mean(predicted_class == y)))
## training accuracy: 0.46
随机查找最优结果参数可以得到的分类准确率是46%,可以知道等样本3分类的随机概率是33%,因此随机查找最优得到了比盲猜要好的结果,虽然其准确率依然不高。其分类结果如下图:
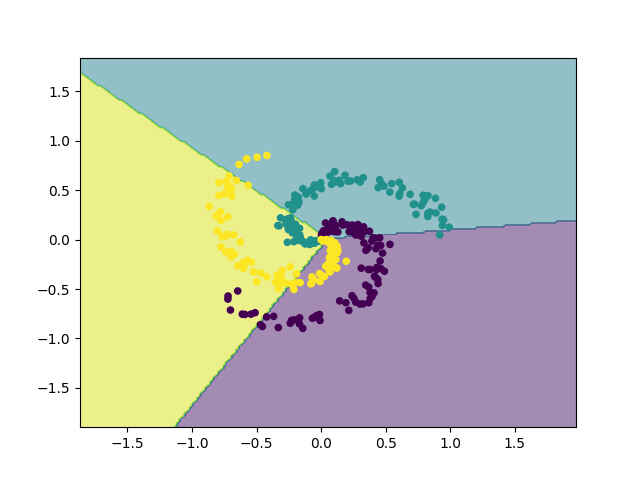
# 3.2局部随机查找参数更新
类比于一个人在山顶迷路了要下山,其每往前走一下其是能够知道这一步是在往下走还是在往上升,只有当迈出的一步可以使得位置下降时才前进一步到达一个新位置,再重新开始寻找下一步。回到参数更新,也可以通过这种Iterative Refinement一步步找寻最优的参数:
reg = 0.001
step_size = 1.
last_loss = float('inf')
W = 0.015 * np.random.randn(D,K)
b = 0.015 * np.random.randn(1,K)
for i in range(10000):
Wt = W + np.random.randn(D,K) * step_size
bt = b + np.random.randn(1,K) * step_size
scores = np.dot(X, Wt) + bt
num_examples = X.shape[0]
# get unnormalized probabilities
exp_scores = np.exp(scores)
# normalize them for each example
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
correct_logprobs = -np.log(probs[range(num_examples),y])
# compute the loss: average cross-entropy loss and regularization
data_loss = np.sum(correct_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(Wt*Wt)
loss = data_loss + reg_loss
if loss < last_loss:
last_loss = loss
W = Wt.copy()
b = bt.copy()
print(f"step: {i} loss: {loss} min loss: {last_loss}")
# evaluate training set accuracy
scores = np.dot(X, W) + b
predicted_class = np.argmax(scores, axis=1)
print('training accuracy: %.2f' % (np.mean(predicted_class == y)))
# training accuracy: 0.56

可以看到使用逐步迭代更新参数的方法,分类的效果得到了一定的提升。
# 3.3 沿着梯度反方向更新
梯度方向是函数值增长最快的方向,那么梯度的反方向就是函数值下降最快的方向。损失函数对参数求导数即可找到损失函数值下降最快的方向,很自然的想到沿着梯度反方向更新参数。
梯度的求解有两种方法:
- 数值解:
- 解析解:即求得函数的导数
- 数值解求解方便,但只是近似结果,有可能有比较大的累积误差,且计算量比较大,而解析解计算较为复杂,推导容易出错。因此通常比较两种梯度计算的结果,以验证梯度计算的是否准确。
reg = 0.0001
step_size = 2
W = np.random.randn(D,K) * 0.001
b = np.random.randn(1,K) * 0.001
for i in range(1000):
scores = np.dot(X, W) + b
num_examples = X.shape[0]
# get unnormalized probabilities
exp_scores = np.exp(scores)
# normalize them for each example
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
correct_logprobs = -np.log(probs[range(num_examples),y])
# compute the loss: average cross-entropy loss and regularization
data_loss = np.sum(correct_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(Wt*Wt)
loss = data_loss + reg_loss
print(f"{i} loss: {loss}")
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
dW = np.dot(X.T, dscores)
db = np.sum(dscores, axis=0, keepdims=True)
dW += reg*W # don't forget the regularization gradient
W += -dW * step_size
b += -db * step_size
# evaluate training set accuracy
scores = np.dot(X, W) + b
predicted_class = np.argmax(scores, axis=1)
print('training accuracy: %.2f' % (np.mean(predicted_class == y)))
# training accuracy: 0.57
受限于线性分类器的能力,使用梯度下降方法对准确率的提升已经不大,但模型学习速度要快的多,经过几十步迭代后,loss就逐渐稳定了,可见梯度反方向的确应该是参数更新的方向,程序中step_size是每一步更新权值大小,也被称为学习率,这也是机器学习中比较关键的参数,后续章节介绍。
step 0 loss: 1.0987081944507475
step 1 loss: 1.035012790265596
step 2 loss: 0.9847131322096168
step 3 loss: 0.9446124386650137
step 4 loss: 0.9122820461040575
step 5 loss: 0.8859083863629116
step 6 loss: 0.8641456746130115
step 7 loss: 0.8459924630117203
step 8 loss: 0.8306977637849042
step 9 loss: 0.8176927238746483
step 10 loss: 0.8065417050365444
step 11 loss: 0.7969073565356761
step 12 loss: 0.7885255785711087
step 13 loss: 0.7811874419263808
step 14 loss: 0.7747260116459382
step 15 loss: 0.7690066494799522
step 16 loss: 0.7639198043202386
step 17 loss: 0.7593755983752785
step 18 loss: 0.7552997218726981
step 19 loss: 0.7516302904789174
step 20 loss: 0.74831541777118
step 21 loss: 0.7453113237504392
step 22 loss: 0.7425808488143958
step 23 loss: 0.7400922770753964
step 24 loss: 0.7378183976522287
step 25 loss: 0.7357357504859927
step 26 loss: 0.7338240163214523
step 27 loss: 0.7320655201385343
step 28 loss: 0.730444824479833
step 29 loss: 0.728948394479751
step 30 loss: 0.7275643204427976
step 31 loss: 0.7262820868888554
step 32 loss: 0.7250923793318111
step 33 loss: 0.7239869218665891
step 34 loss: 0.722958340041463
step 35 loss: 0.7220000445858086
step 36 loss: 0.7211061324211997
step 37 loss: 0.7202713020605488
这里使用的梯度下降算法直接拿所有训练样本参与训练,但对于大规模训练数据,一次性加载计算是不可能实现的,像ILSVRC有120万张图像。此时可以使用mini batch gradient descent算法,每次选择打散数据中batch_size数目的数据参与训练用于更新参数,mini batch gradient descent只所以能够工作,是因为训练数据之间是相关的,考虑极端情况,ILSVRC的120万张图像有1000个类,每个类的1200张图像都是相同的,则此时选一部分数据更新参数与利用所有数据同时参与训练,效果是等效的,实际中虽然相同类别的不同图像不可能完全相同,但其之间是有一定共同特征的,因此使用mini batch gradient descent算法训练模型依然能够收敛。
# 4.链式法则与反向传播
通过#3中的介绍,以线性分类器
以函数:
梯度求解过程:
x=-2; y=5; z=-4
q = x + y # q=3
f = q * z # f=-12
## 反向传播求梯度
dfdz = q # dfdz=3
dfdq = z # dfdq=-4
dqdx = 1
dqdy = 1
dfdx = dfdq * dqdx # dfdx = -4, 此处就是链式法则的应用
dfdy = dfdq * dqdy # dfdx = -4
链式法则的形象化图示如下:

# 5.梯度方向的参数更新策略
- 1.普通梯度下降策略
这里先实现如图1所示的带一层隐含层的全连接神经网络,X是二维特征的数据4个神经元,则3个类别,则
写成矩阵形式:
损失函数使用CrossEntropy,i表示第i个样本,同上述举证形式中的每行,k表示当前样本所属类别:
补充一下,多分类交叉熵损失函数的形式一般写为:
其中,SOFTMAX后输出的在该类别上的评分,One-Hot编码后的向量,如3个类时[0,0,1]。可以看到在不是当前类别的标签上都是0,因此
先对上述全连接神经网络和损失函数应用链式法则求导:
以上就根据链式法则求得了两层全连接神经网络的梯度,对于N个样本输入时,使用矩阵表示可同样推导。根据以上推导实现的两层全连接神经网络为:
H = 100
W = 0.015 * np.random.randn(D,H)
b = np.zeros((1,H))
W1 = 0.015 * np.random.randn(H,K)
b1 = np.zeros((1,K))
reg = 0.001
step_size = 1.5
def sigmoid(x):
return 1/(1+np.exp(-x))
mu = 0.9
v1 = 0
v2 = 0
v3 = 0
v4 = 0
for i in range(5000):
Y = np.dot(X, W) + b
sY = np.maximum(Y, 0)
scores = np.dot(sY, W1) + b1
num_examples = X.shape[0]
# get unnormalized probabilities
exp_scores = np.exp(scores)
# normalize them for each example
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
correct_logprobs = -np.log(probs[range(num_examples),y])
# compute the loss: average cross-entropy loss and regularization
data_loss = np.sum(correct_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W) + 0.5*reg*np.sum(W1*W1)
loss = data_loss + reg_loss
print(f"step: {i} loss: {loss}")
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
print(dscores.shape)
dW1 = np.dot(sY.T, dscores)
db1 = np.sum(dscores, axis=0, keepdims=True)
dW1 += reg*W1
dsY = np.dot(dscores, W1.T)
dsY = dsY * sigmoid(Y)*(1-sigmoid(Y))
dsY[sY<=0] = 0
dW = np.dot(X.T, dsY)
db = np.sum(dsY, axis=0, keepdims=True)
dW += reg*W # don't forget the regularization gradient
# perform a parameter update
# Vanilla update
# step: 5403 loss: 0.30999144570577264
W += - step_size * dW
b += - step_size * db
W1 += - step_size * dW1
b1 += - step_size * db1
使用普通梯度的更新,模型的分类准确率轻松达到了97%。

- 2.动量更新策略
将损失函数类比为丘陵,则势能U=mgh,0,如此,可将优化过程类比为将物体从山顶往下滚。由势能的定义,物体所受的力可通过势能mu表示为物体的动量,通常取0.9。
# Momentum update
v = mu * v - learning_rate * dx # integrate velocity
x += v # integrate position
## 作用在前述全连接神经网络实现上
v1 = mu * v1 - step_size * dW
W += v1
v2 = mu * v2 - step_size * db
b += v2
v3 = mu * v3 - step_size * dW1
W1 += v3
v4 = mu * v4 - step_size * db1
b1 += v4
- 3.
Nesterov动量更新策略
Nesterov Momentum是由俄国数学家Yurii Nesterov提出的凸优化方法,Nesterov Momentum的核心是对于位置x处的参数向量,只看动量部分,其动量对参数向量的贡献部分为mv,当更新梯度时,可以将x+mu*v当做远眺,求x+mu*v处的梯度用以更新参数x,而非使用滞后的位置x处的梯度。
x_ahead = x + mu * v
# evaluate dx_ahead (the gradient at x_ahead instead of at x)
v = mu * v - learning_rate * dx_ahead
x += v
## 通常利用`x_ahead = x + mu * v`将上述表示写为:
v_prev = v # back this up
v = mu * v - learning_rate * dx # velocity update stays the same
x += -mu * v_prev + (1 + mu) * v # position update changes form
## 应用到前述的两层全连接神经网络中
mu = 0.9
v1 = 0
v2 = 0
v3 = 0
v4 = 0
v1p = v1
v1 = mu * v1 - step_size * dW
W += -mu * v1p + (1+mu)*v1
v2p = v2
v2 = mu * v2 - step_size * db
b += -mu * v2p + (1+mu)*v2
v3p = v3
v3 = mu * v3 - step_size * dW1
W1 += -mu * v3p + (1+mu)*v3
v4p = v4
v4 = mu * v4 - step_size * db1
b1 += -mu * v4p + (1+mu)*v4
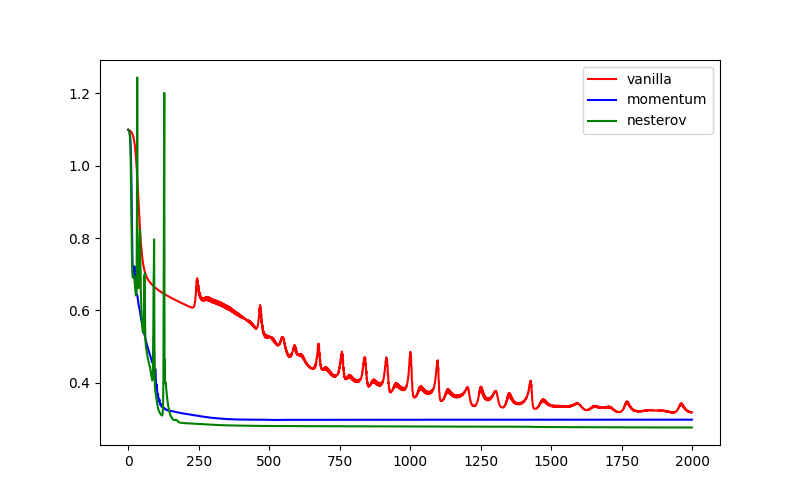
- 4.三种方法对比
将以上三种参数更新方法的优化过程中loss下降情况绘制如下图,可以看到Momentum比Vanilla收敛的要快,Nesterov Momentum收敛过程比较振荡,但收敛的loss更低,收敛的效果的更好。
# 6.学习率退火
# 6.1学习率衰减策略基础
参考如上参数更新过程,学习率过大则每一步更新的参数量过大,会导致模型振荡且收敛于loss较大的状态,学习效果较差;而学习率过小,会导致模型参数更新速度过慢,花费过多训练时间。自然而然的会想到,随着训练step的变大逐步减小学习率,这就是学习率退火的原理。通常有三种学习率的衰减策略:
1.按步衰减:
Step decay,如每5epoches学习率衰减一半,或者20 epochs衰减0.1,一个启发式的办法是使用固定学习率,当验证集上的准确率不再上升时则减小学习率为原来的0.5倍。2.指数衰减:
、 3.
、
# 6.2 二阶优化方法
首先看泰勒定理:

- 牛顿法
对于函数F(x),考虑step=k,假设在
(Hessian Matrix)。前面讨论的优化方法使用的是一阶导数
上述等式右侧是
通过求解以上方程就得到了参数的更新量Hessian Matrix占据的内存太大,目前还不能够直接使用,如对于100M参数的神经网络,其Hessian Matrix维度为
- 高斯牛顿法
对于非线性最小二乘优化问题Hessian Matrix。其原理是将f(x)在
注意这里是对

根据对
可将上述方程写成:
根据其求极值条件,可求得
上述方程被称为增量方程、高斯牛顿方程(Gauss Newton Equation)、正规方程(Normal Equation)。高斯牛顿方法避免了计算二阶梯度,使用
# 6.3自适应学习率方法
虽然前面介绍的二阶梯度方法很好,但因神经网络中参数量、训练数据量巨大,很难应用。像L-BFGS算法需要在整个数据集上同时计算二阶梯度在mini-batch上无法工作。因此,神经网络优化中使用最多的是Nestov Momentum方法加自适应学习率。
Adagrad:该方法是John Duchi于
2011年提出的方法 (opens new window)。# Assume the gradient dx and parameter vector x cache += dx**2 x += - learning_rate * dx / (np.sqrt(cache) + eps)其中,参数
cache和dx有相同的维度,故其可以根据参数更新的大小自适应衰减学习率。缺点是研究表明神经网络过程中使用单调下降的学习率会导致参数下降过快,模型过早的停止收敛。RMSprop: 该方法是机器学习专家Geoff Hinton在其
Cousera课程讲义 (opens new window)中提出,目前并没有发表。# decay_rate是超参数,常取[0.9, 0.99, 0.999] cache = decay_rate * cache + (1 - decay_rate) * dx**2 x += - learning_rate * dx / (np.sqrt(cache) + eps)Adam:该方法是
2014年12月Diederik P. Kingma提出的方法 (opens new window),该方法和带动量的RMSprop有些相似,m = beta1*m + (1-beta1)*dx v = beta2*v + (1-beta2)*(dx**2) x += - learning_rate * m / (np.sqrt(v) + eps)可以看到除了使用
Adam和RMSprop是一样的,其中超参数的常用值为eps = 1e-8,beta1 = 0.9,beta2 = 0.999,一般来说Adam是目前最好的方法,比RMSprop好一些。# ## raw # cw, cb, cw1, cb1 = 1, 1, 1, 1 # ## Adagrad # cw += dW**2 # cb += db**2 # cw1 += dW1**2 # cb1 += db1**2 # ## rmsprop # cw = decay*cw + (1-decay)*dW**2 # cb = decay*cb + (1-decay)*db**2 # cw1 = decay*cw1 + (1-decay)*dW1**2 # cb1 = decay*cb1 + (1-decay)*db1**2 ## Adam t = i + 1 cw = decay*cw + (1-decay)*dW**2 cwt = cw / (1-decay**t) cb = decay*cb + (1-decay)*db**2 cbt = cb / (1-decay**t) cw1 = decay*cw1 + (1-decay)*dW1**2 cw1t = cw1 / (1-decay**t) cb1 = decay*cb1 + (1-decay)*db1**2 cb1t = cb1 / (1-decay**t) mw = dm*cw + (1-dm)*dW mwt = mw / (1-dm**t) mb = dm*cb + (1-dm)*db mbt = mb / (1-dm**t) mw1 = dm*cw1 + (1-dm)*dW1 mw1t = mw1 / (1-dm**t) mb1 = dm*cb1 + (1-dm)*db1 mb1t = mb1 / (1-dm**t) W += - step_size * mwt / (np.sqrt(cwt) + eps) b += - step_size * mbt / (np.sqrt(cbt) + eps) W1 += - step_size * mw1t / (np.sqrt(cw1t) + eps) b1 += - step_size * mb1t / (np.sqrt(cb1t) + eps)
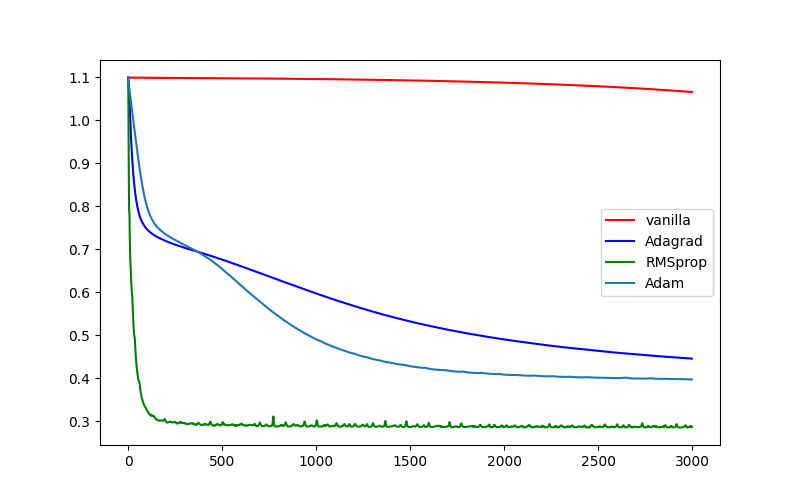
如上实验中,RMSprop和Adam优化效果较好,其中RMSprop比Adam的优化效果还要好些。