# 可变形卷积
# 0.简介
论文:Deformable Convolutional Networks (opens new window)
仓库:https://github.com/msracver/Deformable-ConvNets.git (opens new window)
Deformable Convolutional Networks是清华大学的代季峰 (opens new window)于2017年发表的论文中提出的。主要想解决的问题是,给常规卷积增加一个二维的平移变换,使用可变形的卷积核对特征图进行卷积,提升卷积的表达能力。这篇文章讨论的空间变换表征能力与2015年google的DeepMind发表的STN的有相似之处。
视觉任务中识别对象尺度/角度等几何相关信息的两种方法:
- 一,使用数据增强,生成具有几何变换多样性的训练数据,如对训练数据进行仿射变换,缺点增加了训练时间
- 二,使用具有几何不变性的特征,如SIFT,缺点手动设计的特征在处理复杂的变换时显得不可行
CNN因固定的几何结构(方形卷积核),导致其无法很好的拟合大型未知的变换。
# 1.可变形卷积
# 1.1 常规卷积
二维常规卷积分两步:
- 1)使用一定大小的方形网格(卷积核)
x上采样 - 2)对采样的值和卷积核参数
w进行加权求和
dilation的大小。

以上定义了dilation=1,大小为
则卷积结果特征图y上的任意位置
# 1.2 可变形卷积
上面介绍的常规卷积,其卷积核是方形的,其作用范围也是方形的。但是图像中的对象通常都不是方形的,如果能在方形卷积核每个元素上加上一个偏移向量,将卷积核中的每个点都移动到对象上,然后加权求和,应该能够得到更好的结果。
可变形卷积(Deformable Convolution)正是在常规卷积计算公式上增加了一个位置偏移向量
卷积操作中的第一步,数据采样,对于可变形卷积是在位置
其中
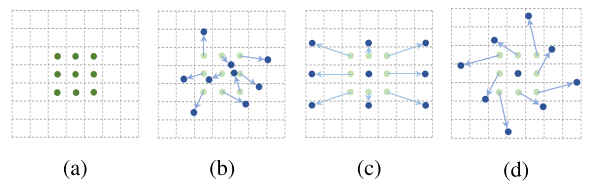
上图中:
- 图
a表示的是常规的方形卷积 - 图
b/c/d表示的是可变形卷积的3个例子,浅蓝色的点表示常规方形卷积核的9个采样点,浅蓝色的箭头表示的是偏移向量,深蓝色的是偏移后的采样点。
# 1.3 可变形卷积层
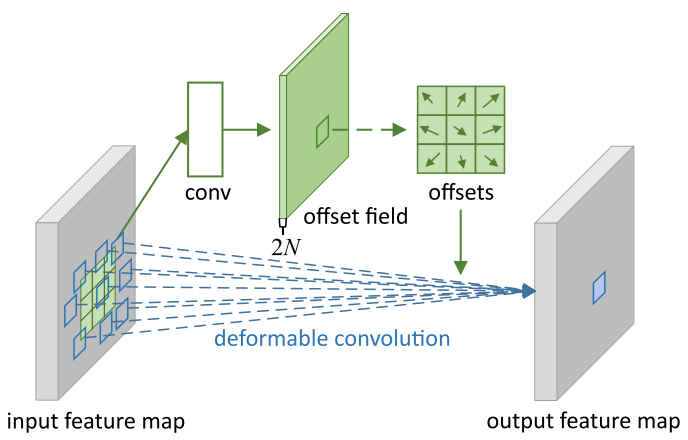
图中蓝色的框表示可变形卷积的采样点,上部的绿色分支是可变形卷积偏移量的获取。其过程为先将通道为N的feature map经过卷积层conv得到通道数为2N的feature map,其中2N表示每个通道x,y方向的偏移量。
代码实现:
借用的是官方仓库用于MXNET框架的可变形卷积Op的实现:DCNv2_op/nn/deformable_im2col.cuh
/*!
* \brief deformable_im2col gpu kernel.
* DO NOT call this directly. Use wrapper function im2col() instead;
*/
template <typename DType>
__global__ void deformable_im2col_gpu_kernel(const int n, const DType* data_im, const DType* data_offset,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
const int dilation_h, const int dilation_w,
const int channel_per_deformable_group,
const int batch_size, const int num_channels, const int deformable_group,
const int height_col, const int width_col,
DType* data_col) {
CUDA_KERNEL_LOOP(index, n) {
// index index of output matrix
const int w_col = index % width_col;
const int h_col = (index / width_col) % height_col;
const int b_col = (index / width_col / height_col) % batch_size;
const int c_im = (index / width_col / height_col) / batch_size;
const int c_col = c_im * kernel_h * kernel_w;
// compute deformable group index
const int deformable_group_index = c_im / channel_per_deformable_group;
const int h_in = h_col * stride_h - pad_h;
const int w_in = w_col * stride_w - pad_w;
DType* data_col_ptr = data_col + ((c_col * batch_size + b_col) * height_col + h_col) * width_col + w_col;
//const DType* data_im_ptr = data_im + ((b_col * num_channels + c_im) * height + h_in) * width + w_in;
const DType* data_im_ptr = data_im + (b_col * num_channels + c_im) * height * width;
const DType* data_offset_ptr = data_offset + (b_col * deformable_group + deformable_group_index) * 2 * kernel_h * kernel_w * height_col * width_col;
for (int i = 0; i < kernel_h; ++i) {
for (int j = 0; j < kernel_w; ++j) {
const int data_offset_h_ptr = ((2 * (i * kernel_w + j)) * height_col + h_col) * width_col + w_col;
const int data_offset_w_ptr = ((2 * (i * kernel_w + j) + 1) * height_col + h_col) * width_col + w_col;
/**
* 在这里可以看到与常规卷积的不同,在于加权求和的采样点是偏移之后的点,
* 而不是方形网格中的点
*/
const DType offset_h = data_offset_ptr[data_offset_h_ptr];
const DType offset_w = data_offset_ptr[data_offset_w_ptr];
DType val = static_cast<DType>(0);
const DType h_im = h_in + i * dilation_h + offset_h;
const DType w_im = w_in + j * dilation_w + offset_w;
if (h_im > -1 && w_im > -1 && h_im < height && w_im < width) {
//const DType map_h = i * dilation_h + offset_h;
//const DType map_w = j * dilation_w + offset_w;
//const int cur_height = height - h_in;
//const int cur_width = width - w_in;
//val = deformable_im2col_bilinear(data_im_ptr, width, cur_height, cur_width, map_h, map_w);
val = deformable_im2col_bilinear(data_im_ptr, width, height, width, h_im, w_im);
}
*data_col_ptr = val;
data_col_ptr += batch_size * height_col * width_col;
}
}
}
从Deformable Convolution的定义调用,可以看到可变形卷积的偏移量是通过卷积操作获得的,并作为可变形卷积的输入。
def model():
res5b_branch2a_relu = mx.symbol.Activation(name='res5b_branch2a_relu', data=scale5b_branch2a, act_type='relu')
res5b_branch2b_offset = mx.symbol.Convolution(name='res5b_branch2b_offset', data = res5b_branch2a_relu,
num_filter=18, pad=(1, 1), kernel=(3, 3), stride=(1, 1), cudnn_off=True)
res5b_branch2b = mx.contrib.symbol.DeformableConvolution(name='res5b_branch2b', data=res5b_branch2a_relu, offset=res5b_branch2b_offset,
num_filter=512, pad=(2, 2), kernel=(3, 3), num_deformable_group=1,
stride=(1, 1), dilate=(2, 2), no_bias=True)
return
# 2.可变形RoI Pooling
# 2.1 常规RoI Pooling
关于常规RoI池化的介绍可以参考这里 (opens new window)。

公式化表示为:
给定特征图RoI,RoI左上角点在RoI Pooling后得到的特征图
其中RoI池化时每个方格中对应的特征图RoI Pooling,则RoI Pooling后得到的特征图大小为RoI Pooling时每个方格对应原特征图上RoI Pooling后的第
以上便是常规RoI Pooling的定义过程。
# 2.2 可变形RoI(Deformable RoI)
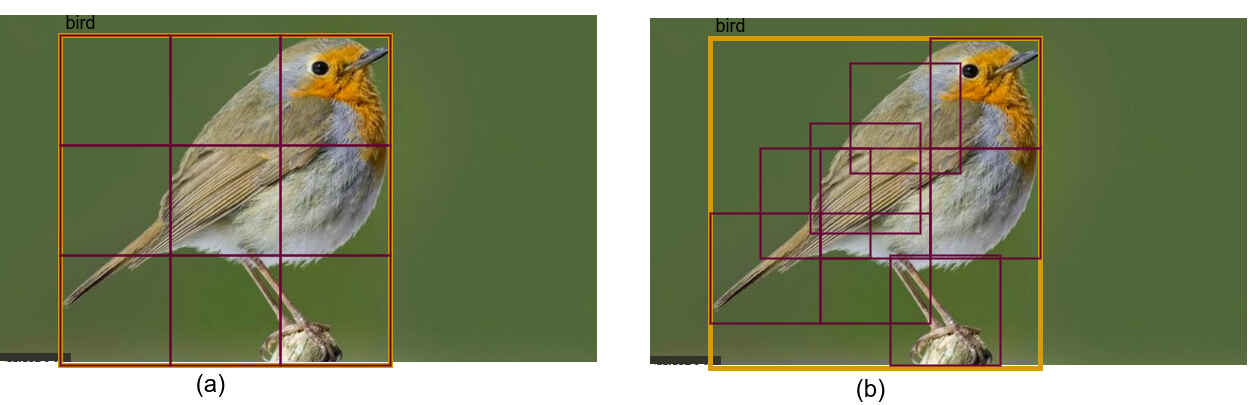
图中(a)是常规RoI Pooling,(b)是对RoI Pooling的每个方格分别进行平移后池化得到结果,即可变形RoI的结果。
与可变形卷积部分相同,可变形RoI Pooling同样是对RoI池化的
可变形RoI Pooling的表达式定义为:
同样,往往
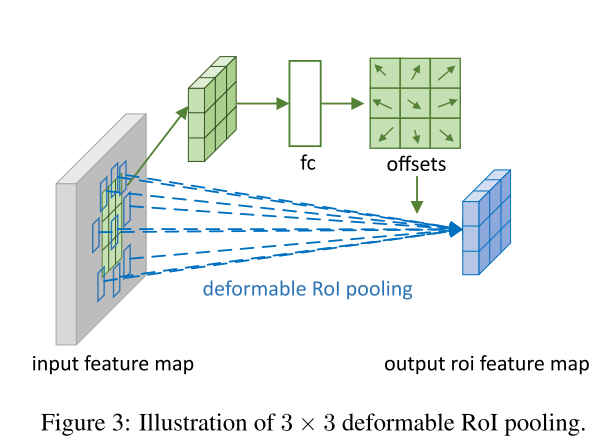
上图描述了Deformable RoI Pooling偏移量的计算方式。
# 2.3 代码实现
参考自文章仓库: Deformable-ConvNets/rfcn/operator_cxx/deformable_psroi_pooling.cu
template <typename DType>
__global__ void DeformablePSROIPoolForwardKernel(
const int count,
const DType* bottom_data,
const DType spatial_scale,
const int channels,
const int height, const int width,
const int pooled_height, const int pooled_width,
const DType* bottom_rois, const DType* bottom_trans,
const bool no_trans,
const DType trans_std,
const int sample_per_part,
const int output_dim,
const int group_size,
const int part_size,
const int num_classes,
const int channels_each_class,
DType* top_data,
DType* top_count) {
CUDA_KERNEL_LOOP(index, count) {
// The output is in order (n, ctop, ph, pw)
int pw = index % pooled_width;
int ph = (index / pooled_width) % pooled_height;
int ctop = (index / pooled_width / pooled_height) % output_dim;
int n = index / pooled_width / pooled_height / output_dim;
// [start, end) interval for spatial sampling
const DType* offset_bottom_rois = bottom_rois + n * 5;
int roi_batch_ind = offset_bottom_rois[0];
DType roi_start_w = static_cast<DType>(round(offset_bottom_rois[1])) * spatial_scale - 0.5;
DType roi_start_h = static_cast<DType>(round(offset_bottom_rois[2])) * spatial_scale - 0.5;
DType roi_end_w = static_cast<DType>(round(offset_bottom_rois[3]) + 1.) * spatial_scale - 0.5;
DType roi_end_h = static_cast<DType>(round(offset_bottom_rois[4]) + 1.) * spatial_scale - 0.5;
// Force too small ROIs to be 1x1
DType roi_width = max(roi_end_w - roi_start_w, 0.1); //avoid 0
DType roi_height = max(roi_end_h - roi_start_h, 0.1);
// Compute w and h at bottom
DType bin_size_h = roi_height / static_cast<DType>(pooled_height);
DType bin_size_w = roi_width / static_cast<DType>(pooled_width);
DType sub_bin_size_h = bin_size_h / static_cast<DType>(sample_per_part);
DType sub_bin_size_w = bin_size_w / static_cast<DType>(sample_per_part);
int part_h = floor(static_cast<DType>(ph) / pooled_height*part_size);
int part_w = floor(static_cast<DType>(pw) / pooled_width*part_size);
int class_id = ctop / channels_each_class;
DType trans_x = no_trans ? static_cast<DType>(0) :
bottom_trans[(((n * num_classes + class_id) * 2) * part_size + part_h)*part_size + part_w] * trans_std;
DType trans_y = no_trans ? static_cast<DType>(0) :
bottom_trans[(((n * num_classes + class_id) * 2 + 1) * part_size + part_h)*part_size + part_w] * trans_std;
DType wstart = static_cast<DType>(pw)* bin_size_w
+ roi_start_w;
wstart += trans_x * roi_width;
DType hstart = static_cast<DType>(ph) * bin_size_h
+ roi_start_h;
hstart += trans_y * roi_height;
DType sum = 0;
int count = 0;
int gw = floor(static_cast<DType>(pw) * group_size / pooled_width);
int gh = floor(static_cast<DType>(ph)* group_size / pooled_height);
gw = min(max(gw, 0), group_size - 1);
gh = min(max(gh, 0), group_size - 1);
const DType* offset_bottom_data = bottom_data + (roi_batch_ind * channels) * height * width;
for (int ih = 0; ih < sample_per_part; ih++) {
for (int iw = 0; iw < sample_per_part; iw++) {
DType w = wstart + iw*sub_bin_size_w;
DType h = hstart + ih*sub_bin_size_h;
// bilinear interpolation
if (w<-0.5 || w>width - 0.5 || h<-0.5 || h>height - 0.5) {
continue;
}
w = min(max(w, 0.), width - 1.);
h = min(max(h, 0.), height - 1.);
int c = (ctop*group_size + gh)*group_size + gw;
DType val = bilinear_interp(offset_bottom_data + c*height*width, w, h, width, height);
sum += val;
count++;
}
}
top_data[index] = count == 0 ? static_cast<DType>(0) : sum / count;
top_count[index] = count;
}
}
这里给出的代码是Position Sensative RoI Pooling的可变形操作,是作者另一篇文章中提出的一种RoI Pooling方式,其中group参数可以暂时忽略,其余部分就是可变形RoI的实现过程。
调用:
rfcn_cls_offset_t = mx.sym.Convolution(data=relu_new_1, kernel=(1, 1), num_filter=2 * 3 * 3 * num_classes, name="rfcn_cls_offset_t")
rfcn_bbox_offset_t = mx.sym.Convolution(data=relu_new_1, kernel=(1, 1), num_filter=3 * 3 * 2, name="rfcn_bbox_offset_t")
rfcn_cls_offset = mx.contrib.sym.DeformablePSROIPooling(name='rfcn_cls_offset', data=rfcn_cls_offset_t, rois=rois, group_size=3, pooled_size=3,
sample_per_part=4, no_trans=True, part_size=3, output_dim=2 * num_classes, spatial_scale=0.0625)
rfcn_bbox_offset = mx.contrib.sym.DeformablePSROIPooling(name='rfcn_bbox_offset', data=rfcn_bbox_offset_t, rois=rois, group_size=3, pooled_size=3,
sample_per_part=4, no_trans=True, part_size=3, output_dim=2, spatial_scale=0.0625)
# 3.后记
可变形卷积相当于尽量对图像中对象上的像素进行操作,减少对背景像素的操作。这种通过在网络中定义变换运算,然后对网络进行视觉任务的端到端训练后即可使得网络中定义的运算具有变换能力,这是一种非常奇妙的操作,因为并没有对网络中定义的变换运算进行有监督的训练,这里应该是一件值得探讨的点。