# 1.生成器Generator
在2001创建的PEP255 (opens new window)中引入的,生成器函数是返回懒加载迭代器的函数,使用上像list,但与list不同的时,生成器中保存的不是元素的值而是生成元素的逻辑关系,所以使用生成器能够节省内存。
使用生成器的几个例子:
- 读取大文件:
csv_gen = csv_reader("some_csv.txt")
row_count = 0
for row in csv_gen:
row_count += 1
print(f"Row count is {row_count}")
通过普通的方式定义csv_reader函数时会因为读取的文件过大导致内存耗尽:
def csv_reader(file_name):
file = open(file_name)
result = file.read().split("\n")
return result
因为要把csv文件的每行都读取到result中,内存不够时将会导致报错:
Traceback (most recent call last):
File "ex1_naive.py", line 22, in <module>
main()
File "ex1_naive.py", line 13, in main
csv_gen = csv_reader("file.txt")
File "ex1_naive.py", line 6, in csv_reader
result = file.read().split("\n")
MemoryError
通过使用生成器,能够避免这种问题,定义csv_reader函数如下:
def csv_reader(file_name):
for row in open(file_name, "r"):
yield row
生成器中会保留读取的文件句柄,不会重复的open文件,又不会加载文件中的内容,因此需要的内存也比较少。
- 生成一个无穷序列
def infinite_sequence():
num = 0
while True:
yield num
num += 1
gen = infinite_sequence()
for i in range(3):
print(next(gen))
# 0
# 1
# 2
- 生成器表达式
通过圆括号表达式生成生成器。
import sys
nums_squared_lc = [num**2 for num in range(100)]
print(sys.getsizeof(nums_squared_lc))
# 920
nums_squared_gc = (num**2 for num in range(100))
print(sys.getsizeof(nums_squared_gc))
# 112
可以看到生成器所需要的内存比普通迭代器容器需要的少的多。
# 2.yield语句
yield语句用于生成器函数中,其功能有些类似于普通函数中的return语句,主要用来控制生成器函数的逻辑流。
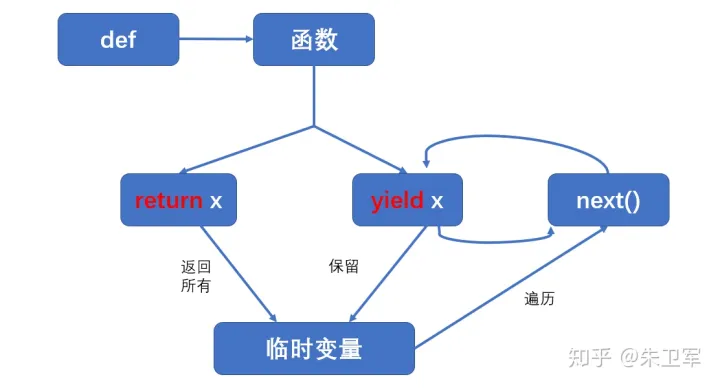
使用yield语句的函数返回的是一个生成器,当每次使用next的函数去获取生成器中的值时,每次生成器函数都会执行到yield的语句,只到再次迭代或next生成器。
当执行到yield语句时,函数返回yield的值,并将函数的状态挂起,会将生成器函数相关的任何局部变量保存起来,包括指针,函数的栈,和异常,如前面读取文件的上下文句柄。