# STDC Net分割算法
# 1.简介
论文地址:https://arxiv.org/abs/2104.13188 (opens new window)
仓库地址:https://github.com/MichaelFan01/STDC-Seg (opens new window)
STDCMNet(Short Term Dense Concatenate Network)网络是美团2021年04月27号提交的论文Rethinking BiSeNet For Real-time Semantic Segmentation中提出的轻量级语义分割网络,该网络是在BiSeNet v1/v2基础上的升级改进。STDCNet主要贡献有两点,一方面是对骨干网络backbone的改进,改成了Dense Concatenate的模块结构,同一个STDC模块中,每个ConvX随着感受野的变大输出的通道数逐渐变少,最后再Concatenate到一起,因此包含更多的特征尺度信息。另一方面是多分支低阶细节信息辅助训练结构,detail information guidance结构只在训练的时候使用,网络训练完成后可以直接舍弃,这种方法相对于之前的BiSeNnet可以减少推理时的计算量。
# 2.网络结构
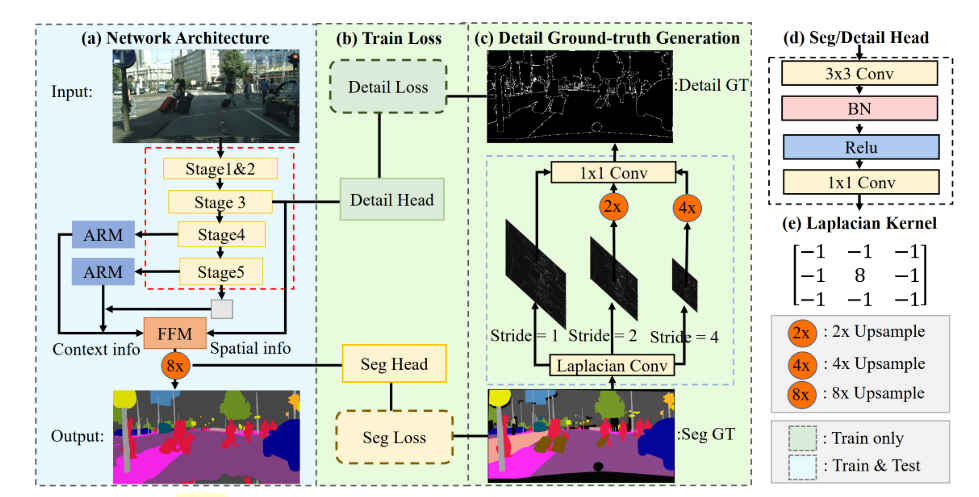
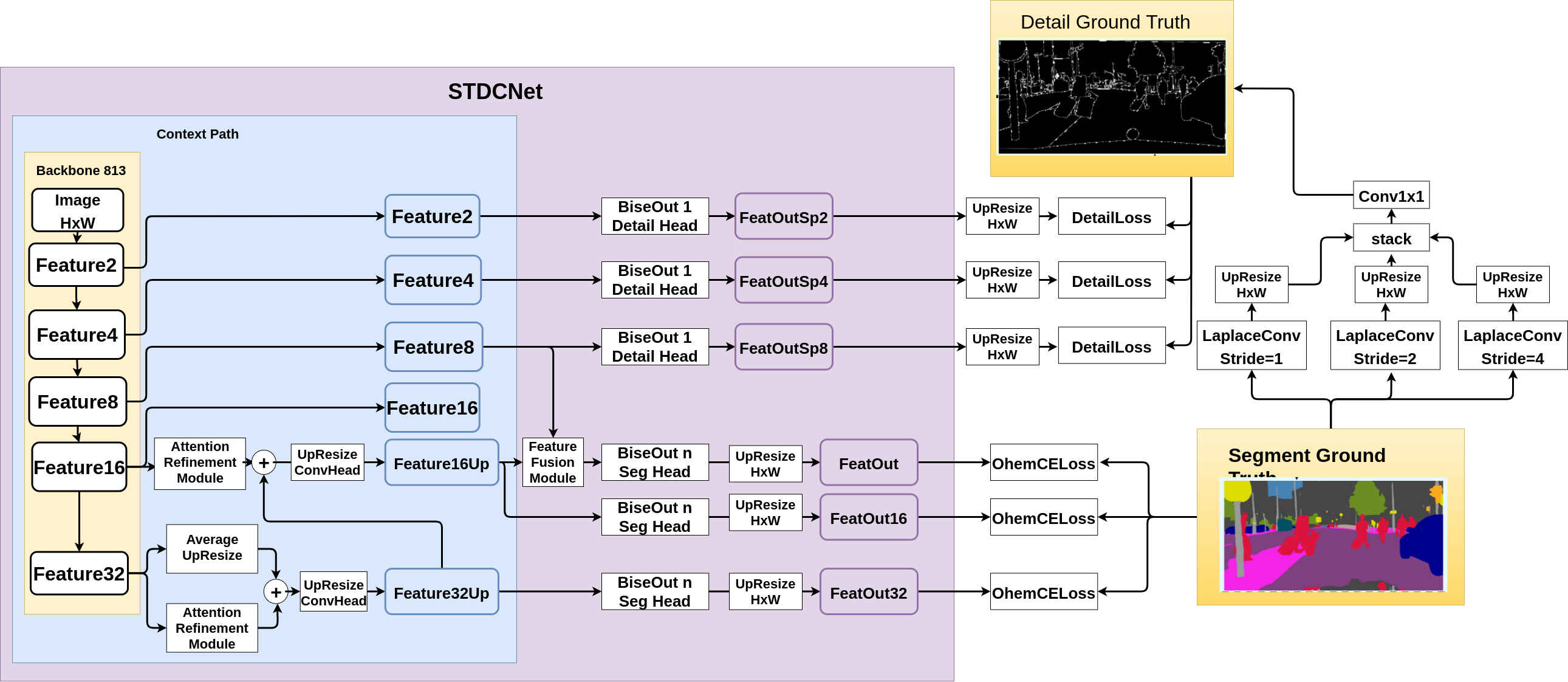
如上图,网络的backbone包含5个stage,第i个stage的输出feature map的尺寸是原来的satge 4&5输出的feature map经过ARM(Attention Refine Module)之后包含更多的语义信息,组成context path,前3个stage输出的feature map包含更多的图像细节信息,两者特征融合经SegHead后直接向上最近邻resize输出最终的分割图。Seg Loss使用的是OhemLoss。网络对于低层stage使用Detail Loss做训练,以提升低层stage feature map提取图像细节信息的能力。对于前3个stage输出的feature map使用与SegHead同样结构的Detail Head做处理得到Detail的输出用来计算Detail Loss,**值得注意的是SegHead输出的最终channels数量是分割的类别数,而Detail Head输出的channels数是1,即是边缘的置信度。**计算Detail Loss时,先对ground truth做stride=[1,2,4]的Laplacian Convolution,将不同size的卷积结果再stack到一起,经过3个可训练的1x1的卷积后得到Detail Ground Truth用来计算Detail Loss。根据源码,从网络输出的角度整理出来的网络结构如下图:
# 2.1 Detail Guidance
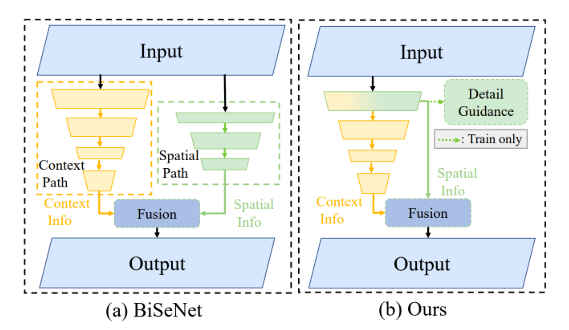
如上图橙色倒金字塔中表示不同stage卷积输出的feature map,从上到小feature map的size逐渐变小,channel逐渐变大。在前几个stage输出的feature map尺度更大,包含了更多的图像细节信息,STDCNet的创新之一就是,增加了Detail Guidance Traning分支,训练时对前几个stage输出的特征图计算loss来提升低层卷积对图像细节提取的能力,这一部分如上图中所示,只在训练时有用,在推理时,直接取低层卷积的feature map与包含更多语义信息的高层卷积feature map做融合,相对于BiSeNet减少了推理时的计算量,提升了模型的推理速度。
Detail Guidance辅助训练可以参考图2,其对stage 1/2/3输出的feature 2/4/8来做训练,提升的是模型低层卷积提取图像细节信息的能力,Detail Ground Truth的生成也可参考图2。
Detail Guidance是对图像边缘做训练故只有2个类,可以使用二分类交叉熵损失函数,如图中所示,Detail Ground Truth中大部分都是黑色的背景,只有少量的表示边缘的像素,因此是严重的类别不平衡问题。
detail,其中,
0,通常取1。dice loss计算参考:
def dice_loss_func(input, target):
smooth = 1.
n = input.size(0)
iflat = input.view(n, -1)
tflat = target.view(n, -1)
intersection = (iflat * tflat).sum(1)
loss = 1 - ((2. * intersection + smooth) /
(iflat.sum(1) + tflat.sum(1) + smooth))
return loss.mean()
# 2.2 Short Term Dense Concatenate
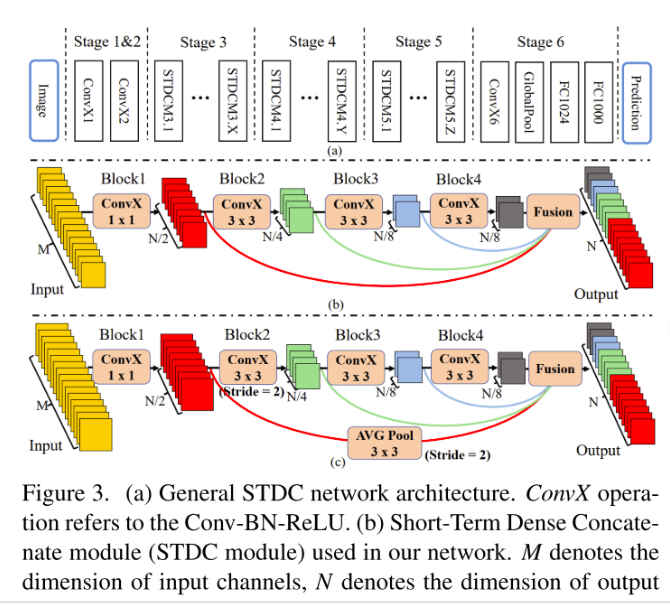
如上图,图a中表示的是网络backbone的整体结构,网络总共分成了6个stage,其中前5个stage用作分割的backbone,第i个stage输出的特征图的大小为原来feature map的通道逐渐变大,为stage 2输出的特征图通道数大于64时,会对stage 5的输出增加一个last_conv,只是为了使stage 5输出特征图的通道数不少于1024。图b表示的是每个stage中使用的Short Dense Concatenate Module,从图中可以看到每个STDCModule包括4个ConvX Block,且卷积所属层级越高,输出的通道数越少,最后将这些不同卷积的输出再直接Concatenate到一起,论文中有一段介绍,STDC的理由是低层卷积感受野小需要更多的通道来提取细节信息,高层卷积有更大的感受野,只需较小的通道数即可得到足够的语义信息。
# 3.其他
# 3.1 Attention Refine Module
Attention Refine Module是BiSeNet (opens new window)中提出的结构,用于ContextPath中,衡量feature map每个通道上的重要程度,其计算过程是先把输入feature经过kernel=3,stride=1,padding=1的卷积,再通过Global Average Pool处理输出NxCx1x1的张量,后对其经过stride=1,kernel=1,bias=False的卷积和Sigmoid的函数,输出元素值在0-1上的评分张量NxCx1x1,取此张量与原feature相乘,得到最后对每个通道上乘以评分后的输出。
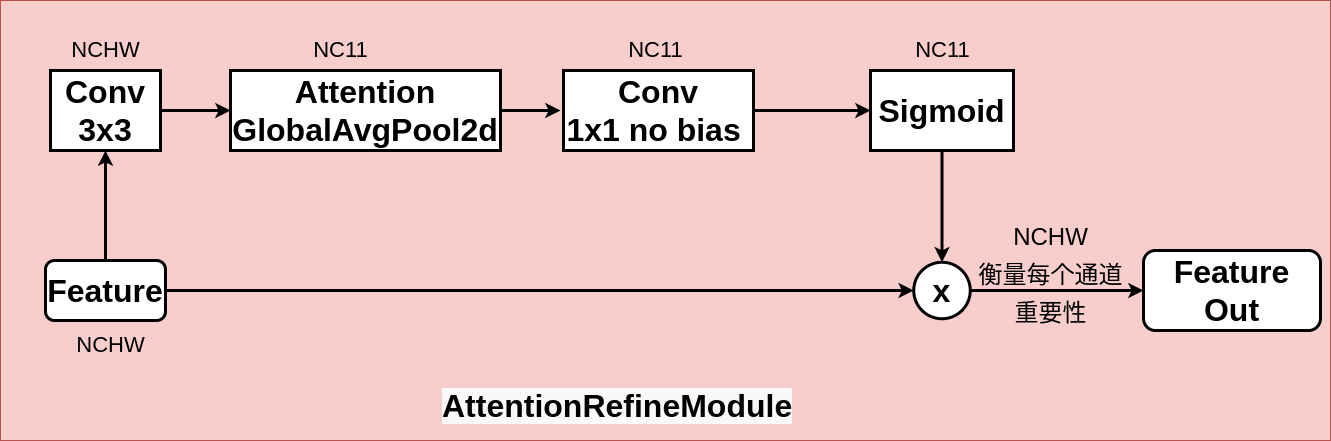
源代码实现:
class AttentionRefinementModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(AttentionRefinementModule, self).__init__()
self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
# self.bn_atten = BatchNorm2d(out_chan)
self.bn_atten = BatchNorm2d(out_chan, activation='none')
self.sigmoid_atten = nn.Sigmoid()
self.init_weight()
def forward(self, x):
feat = self.conv(x)
atten = F.avg_pool2d(feat, feat.size()[2:])
atten = self.conv_atten(atten)
atten = self.bn_atten(atten)
atten = self.sigmoid_atten(atten)
out = torch.mul(feat, atten)
return out
# 3.2 FeatureFusionModule
在STDCNet中,因其同BiSeNet结构,分成了Spatial Path和Context Path,Feature Fusion Module特征融合模块将下采样8倍的Spatial Path和Context Path上的feature map融合到一起得到最终的分割效果,使分割结果即包含足够的细节也还能保持好的语义信息。FFM也是BiSeNet中提出的。
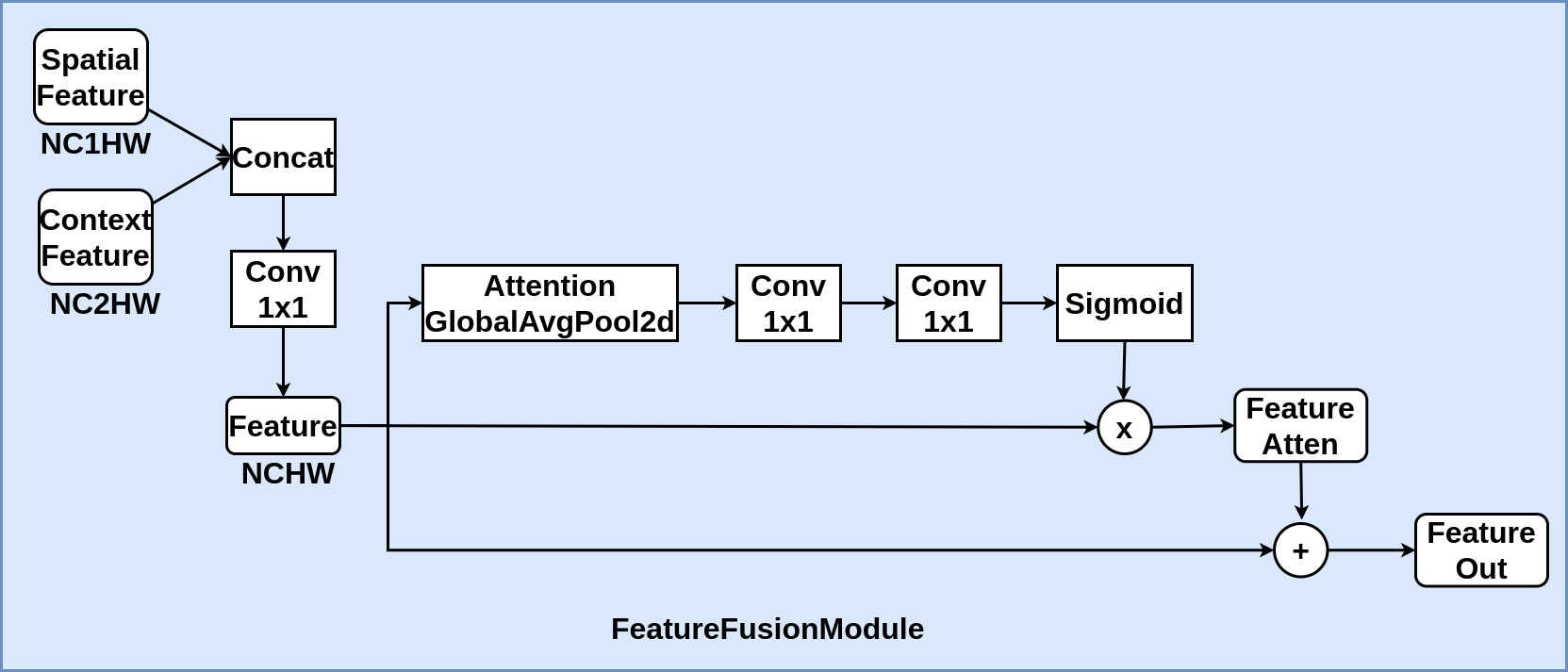
class FeatureFusionModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(FeatureFusionModule, self).__init__()
self.convblk = ConvBNReLU(in_chan, out_chan, ks=1, stride=1, padding=0)
self.conv1 = nn.Conv2d(out_chan,
out_chan//4,
kernel_size = 1,
stride = 1,
padding = 0,
bias = False)
self.conv2 = nn.Conv2d(out_chan//4,
out_chan,
kernel_size = 1,
stride = 1,
padding = 0,
bias = False)
self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
self.init_weight()
def forward(self, fsp, fcp):
fcat = torch.cat([fsp, fcp], dim=1)
feat = self.convblk(fcat)
atten = F.avg_pool2d(feat, feat.size()[2:])
atten = self.conv1(atten)
atten = self.relu(atten)
atten = self.conv2(atten)
atten = self.sigmoid(atten)
feat_atten = torch.mul(feat, atten)
feat_out = feat_atten + feat
return feat_out
可以看到ARM和FFM结构上有一定的相似性,都属于通道注意力机制,作者在[知乎]上回复评论时指出,这两部分灵感都是来源于2017年9月份提出的SeNet (opens new window)。
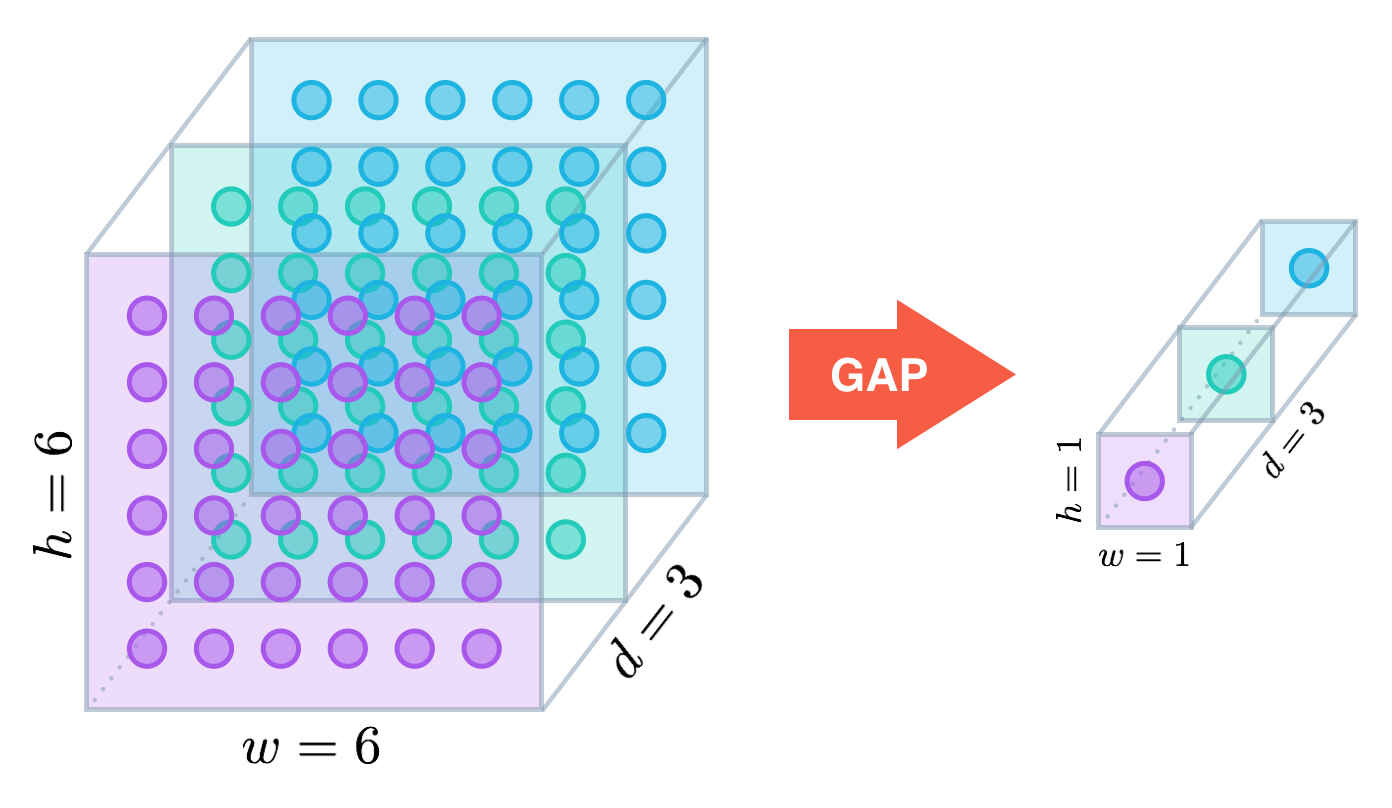
# 3.3 Global Average Pooling
GAP,Global Average Pooling,即全局均值池化,就是说,均值池化是作用在整张feature map上的,即输入特征图的shape为NXCXHW,经池化后,输出的shape为NXCX1X1,即池化核的大小是整张特征图,因此称之为全局均值池化,同理理解GMP,Global Maximum Pooling。[GAP]最早是在2013年12月提交的Network in Network (opens new window)论文中提出用来替代全连接层的,具体可以参考这篇博客 (opens new window)
图片来自于博客
代码实现:
import torch
import torch.nn.functional as F
s = torch.randint(0, 255, (1, 1, 4, 4)).type(torch.float)
print(f"before GAP: {s}")
avg_s = F.adaptive_avg_pool2d(s, (4, 4))
print(f"after GAP: {avgs}")
# before GAP: tensor([[[[ 13., 125., 111., 98.],
# [ 77., 17., 227., 10.],
# [ 54., 253., 252., 118.],
# [110., 33., 99., 233.]]]])
# after GAP: tensor([[[[129.4658]]]])
其中torch.nn.functional.adaptive_average_pool函数的实现方式参考Question (opens new window)介绍,其原理,
# 3.2 OHEM Loss
OHEM Loss (Online Hard Example Mining Loss)同Focal Loss最初提出都是用来解决检测问题中Positive Proposal Boxes和Negative Proposal Boxes类别不平衡问题的,在STDCNet中,对分割输出的训练使用了OHEM Loss。OHEM Loss在训练过程中,不是使用一个batch中所有的样本来计算损失,而是只使用了损失值较大的一部分样本参与计算损失,这个过程发生在整个训练中,因此是一种online的方法。因其计算loss时会选择损失值大对训练影响大的样本的,因此其能够处理样本不平衡问题。OHEM Loss是Fast RCNN作者Ross Girshick等在2016.04发表的论文Training Region-based Object Detectors with Online Hard Example Mining中提出的。
源代码定义的OHEM Loss:
class OhemCELoss(nn.Module):
def __init__(self, thresh, n_min, ignore_lb=255, *args, **kwargs):
super(OhemCELoss, self).__init__()
self.thresh = -torch.log(torch.tensor(thresh, dtype=torch.float)).cuda()
self.n_min = n_min
self.ignore_lb = ignore_lb
self.criteria = nn.CrossEntropyLoss(ignore_index=ignore_lb, reduction='none')
def forward(self, logits, labels):
N, C, H, W = logits.size()
loss = self.criteria(logits, labels).view(-1)
loss, _ = torch.sort(loss, descending=True)
if loss[self.n_min] > self.thresh:
loss = loss[loss>self.thresh]
else:
loss = loss[:self.n_min]
return torch.mean(loss)
# 3.3 卷积感受野
在机器视觉领域的深度神经网络中有一个概念叫做感受野,用来表示网络内部的不同位置的神经元对原图像的感受范围的大小。通俗的说,感受野就是输入图像对这一层输出的神经元的影响有多大。如以下图片所示,图片来自于博客 (opens new window)。
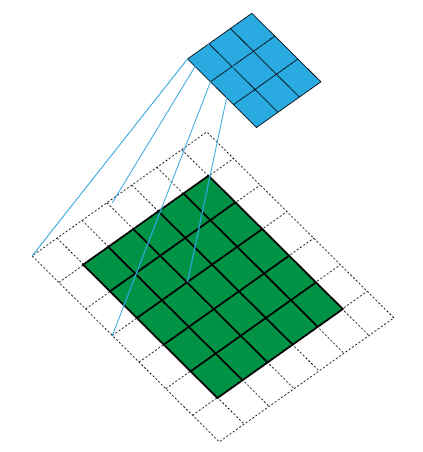
第1层3x3卷积stride=2,RF=3
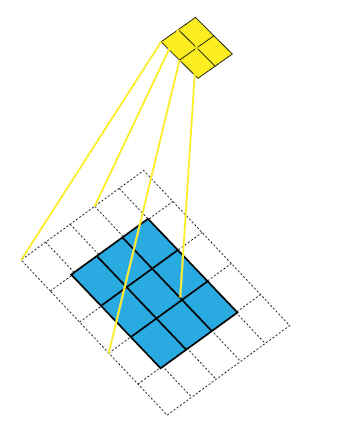
第2层3x3卷积stride=2,RF=7
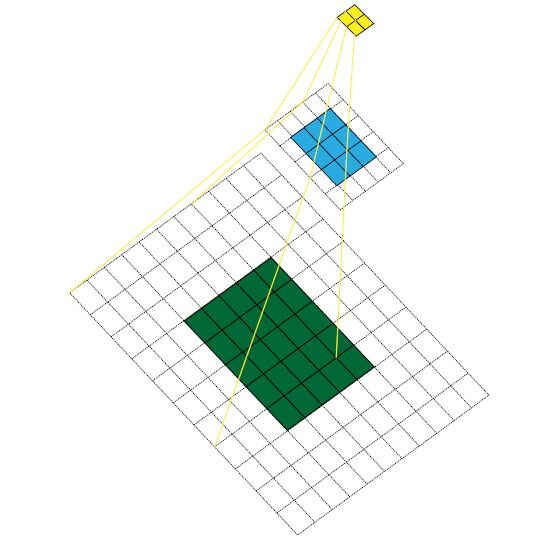
黄色feature map对应的感受野是7*7
感受野Receptive Field的计算公式为:i表示第i个卷积层,kernel和stride是当前层的卷积参数。当然,这里没有考虑padding和pooling及dilation,只讨论了普通的卷积。
# 3.4 分割效果的评估
常用的分割效果评价指标有:
- 像素准确率(Pixel Accuracy,PA),即分类正确的像素数除以总的像素数,同
Accuracy
其中k表示的是分割分类的类别数,i行j列上的数目,PA同accuracy。
- 交并比(Intersection of Union, IoU),即
ground truth和prediction之间计算的比值,又称Jaccard Index雅喀尔指数。
其中,TP是True Positive,FP是False Positive, FN 是False Negative。常用的指标是mean IoU, mIou是计算各个类别上的IoU求平均所得,同样的有mPA,见博客 (opens new window)。mIoU没有考虑类别间像素数量差别较大时的情况,对类别不平衡时有可能会失真,可考虑带权重mIoU。
参考STDCNet源码中计算mIoU的代码:
class MscEval(object):
def evaluate(self):
## evaluate
n_classes = self.n_classes
hist = np.zeros((n_classes, n_classes), dtype=np.float32)
dloader = tqdm(self.dl)
if dist.is_initialized() and not dist.get_rank()==0:
dloader = self.dl
for i, (imgs, label) in enumerate(dloader):
N, _, H, W = label.shape
probs = torch.zeros((N, self.n_classes, H, W))
probs.requires_grad = False
imgs = imgs.cuda()
for sc in self.scales:
# prob = self.scale_crop_eval(imgs, sc)
prob = self.eval_chip(imgs)
probs += prob.detach().cpu()
probs = probs.data.numpy()
preds = np.argmax(probs, axis=1)
hist_once = self.compute_hist(preds, label.data.numpy().squeeze(1))
hist = hist + hist_once
IOUs = np.diag(hist) / (np.sum(hist, axis=0)+np.sum(hist, axis=1)-np.diag(hist))
mIOU = np.mean(IOUs)
return mIOU