# Fully Convolutional Networks for Semantic Segmentation
# 1.基础介绍
论文:Fully Convolutional Networks for Semantic Segmentation (opens new window)
Fully Convolutional Networks, FCN是2014年11月UC Berkeley的Jonathan Long等提交的论文中提出的。论文的主要工作是设计了用于语义分割的全卷积网络结构,能够实现端到端的训练,输出逐像素的稠密预测结果。因为使用了全卷积结构,可以不用限制输入的大小。全卷积网络借用了分类网络的预训练权重,在下采样特征提取部分可以使用分类网络模型的权重。
FCN网络中作者的主要工作有三部分:
- 1)将分类网络转换成用于分割任务的全卷积网络
- 2)使用转置卷积进行上采样得到分割输出,不再同以往的方法使用
shift-stitch方法 - 3)将低层的空间信息和高层的语义信息相融合,fuse what and where information
# 2.分类网络转换成全卷积分割网络
分类任务中,网络模型中多使用了全连接层,因此要求固定的网络输入,如alexnet/vgg/googlenet等,作者认为,全连接和卷积操作是类似的,都是加权求和,只不过全连接层应当被看成感受野是整个特征图的卷积层。将全连接层换成卷积层,可以给模型任意大小的输入,输出相应大小的分割图。
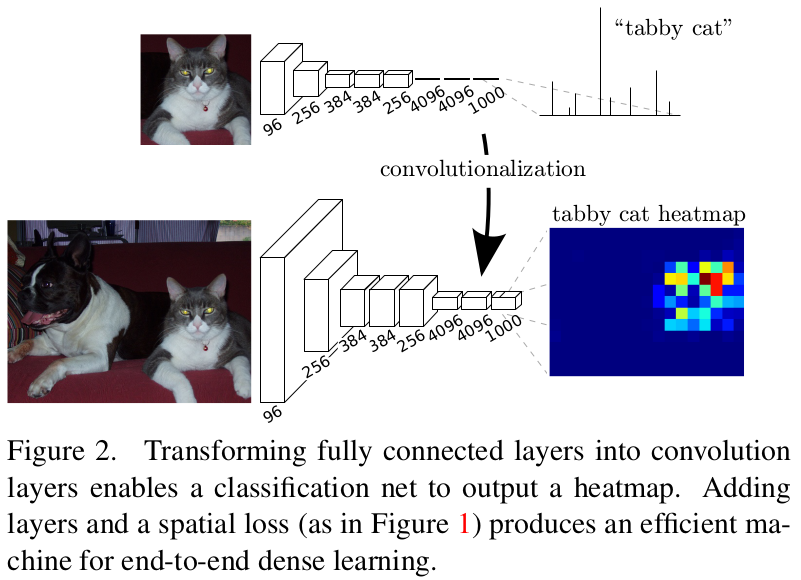
如上图,移除特征提取后的全连接层前的flatten操作,将全连接换成卷积层,在这里可以得到10x10的带空间位置信息的预测热力图。
通过对此添加上采样层,并对网络使用带空间信息的损失函数,可以得到用于语义分割的全连接网络模型:
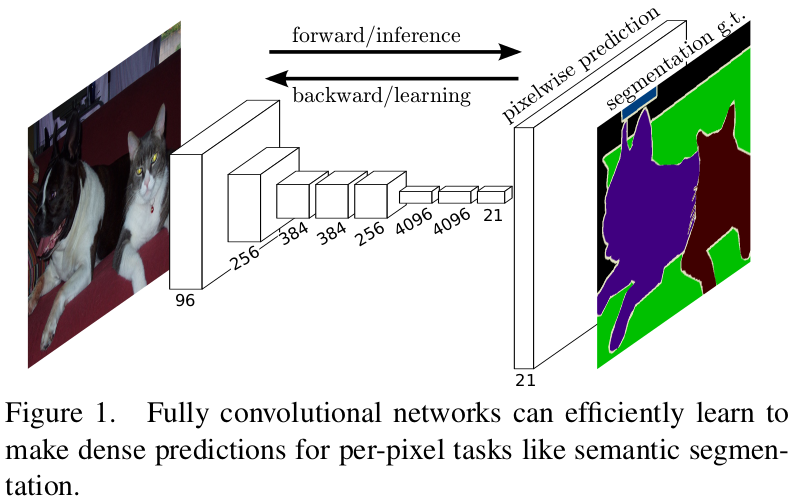
如上图就是一个可以端到端训练的全卷积语义分割模型。
# 3.转置卷积进行上采样
使用分类网络进行特征提取的过程中,使用了池化层,对特征图进行了下采样,这会导致细节信息的丢失,导致得到的分割结果比较粗糙。在以往的分割算法中,对于这种情况使用的是shift-stitch方法。
假设降采样因子为s,那么output map(这里为了简单起见,仅考虑二维)的spatial size则是input的 1/s,向左或向上(向右向下情况一样平移input map,偏移量为(x,y), 其中,
设网络只有一层 2x2 的maxpooling 层且 stride = 2,所以下采样因子 为2, 我们需要对input image 的 pixels 平移 (x,y)个单位,即将 image 向左平移 x 个pixels , 再向上平移y个单位,整幅图像表现向左上方向平移,空出来的右下角就以0 padding 。我们当然可以采取 FCN论文中的做法,将图像向右下角平移,空出来的左上角用 0 padding ,这两种做法产生的结果是一致的,没有本质区别。(x,y) 取(0,0), (0,1),(1,0),(1,1) 后,就产生了
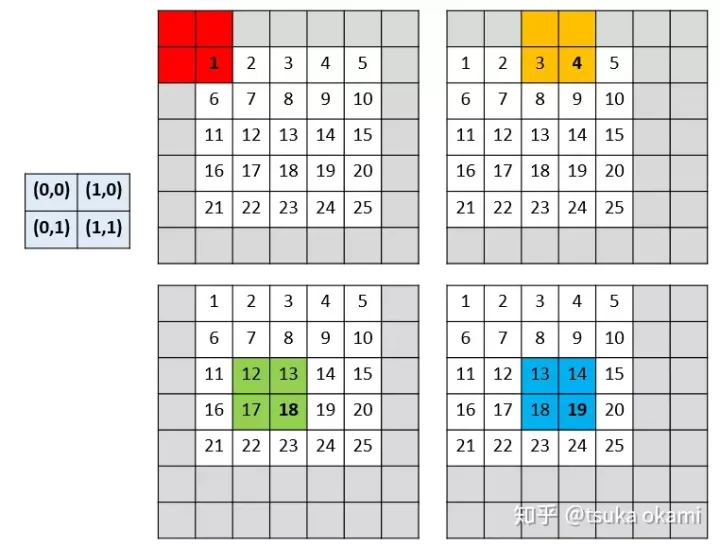
4个input分别进行 2x2 的maxpooling操作后,共产生了4个output,
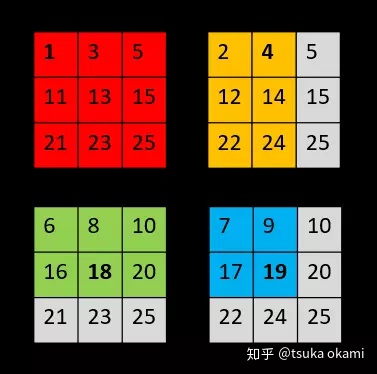
最后,stitch the 4 different output获得dense prediction,
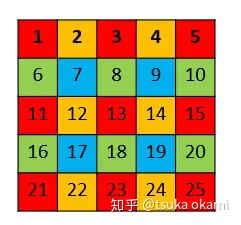
以上就是
shift-and-stitch的过程,引用自1 (opens new window)
以上可以看到,对于一个图像需要输入预测
在FCN中作者使用转置卷积作为上采样层,通过可学习的参数对特征图进行插值上采样,能够得到更好的结果。
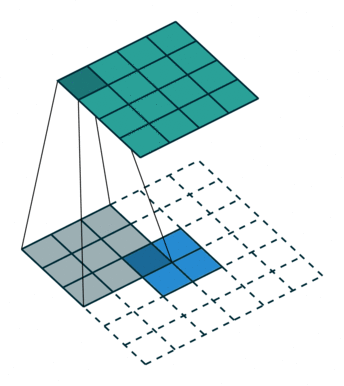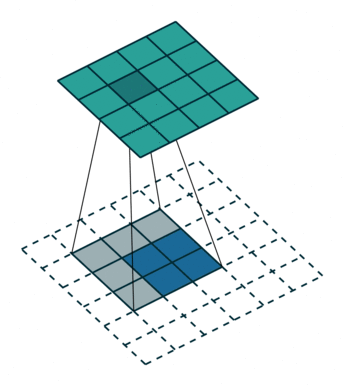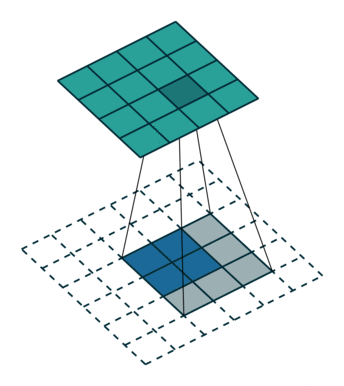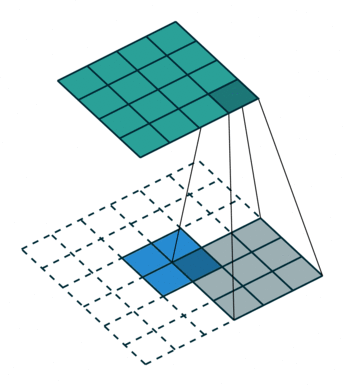
关于转置卷积的详细介绍可以参考3.转置卷积 (opens new window)
# 4.特征融合
作者在论文中还提到的是combine what and where,具体是指在分类网络的特征提取下采样过程中,随着网络变深,卷积感受野变大,因此,高层卷积的特征图中包含更多的语义信息(更有全局视野,空间信息丰富,know where),而低层卷积的特征图包含更多的细节信息(know what),为了改善语义分割的结果,自然的想法就是将低层和高层特征图信息相融合。
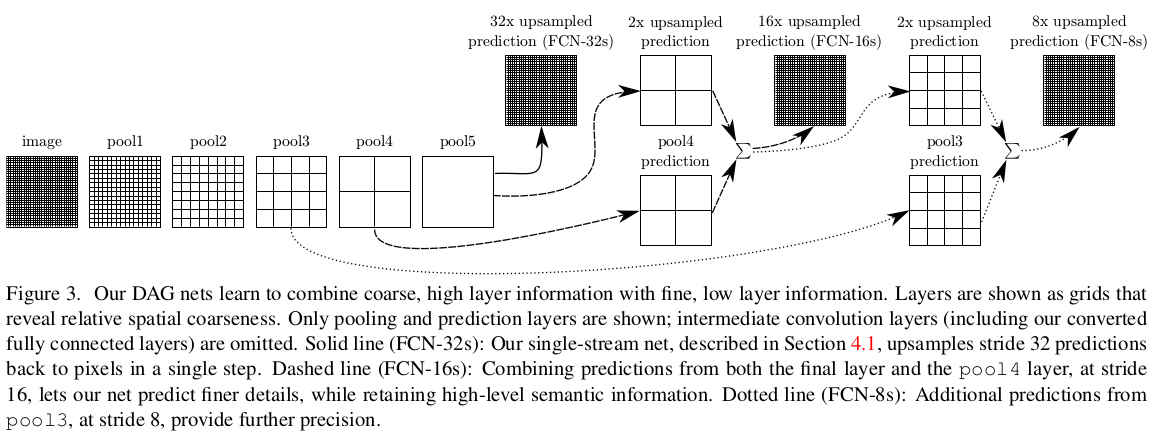
在这里FCN-32s直接将pooling5层的输出进行32倍上采样得到的分割结果,FCN-16s是将pooling4的结果和pool5的结果2x上采样后element-wise求和得到的,同样的方式可以得到FCN-8s。作者在实验部分也指出了,融合what and where特征后输出的分割结果更好,如下图所示。
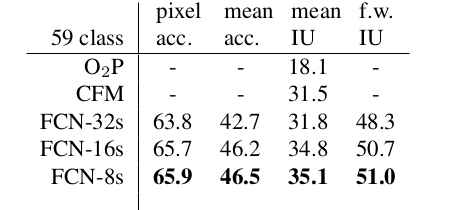
在这里特征融合使用的方式是size相同的特征图,元素间相加求和,如此将低层卷积的结果传递给高层特征图,这种方式和ResNet的恒等映射思想有些相似,不过ResNet是2015年12月提交的论文。除了element-wise求和外,还有不少论文使用的是concatenation on channel,像2015年05月份的U-Net,2021年04月份的STDCNet等。
# 5.一个pytorch源码实现
class FCN16s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5']
x4 = output['x4']
score = self.relu(self.deconv1(x5))
score = self.bn1(score + x4)
score = self.bn2(self.relu(self.deconv2(score)))
score = self.bn3(self.relu(self.deconv3(score)))
score = self.bn4(self.relu(self.deconv4(score)))
score = self.bn5(self.relu(self.deconv5(score)))
score = self.classifier(score)
return score
# 参考资料
← U-Net STDC Net分割算法 →