# CTC算法
# 1.基础介绍
这是2006年第23次ICML会以上的一篇论文。
很多实际应用需要从未切分的数据中输出序列信息,如语音识别中的语音转文字,光学字符识别(Optical character recognition,OCR)中的字符图片转字符序列。循环神经网络(Recurrent neural networks,RNN)十分适合序列数据的学习,但其训练数据要求必须是切分后的序列,而实际应用中切分的训练序列数据标注比较困难,是很难获取的。
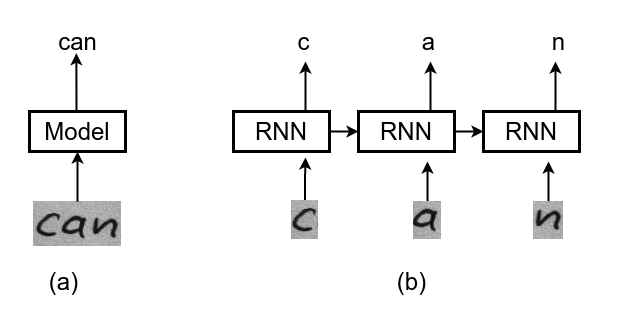
上图是OCR的两种模型,一种如图(a)可直接输入OCR检测得到的图片得到图片中的字符串can,另外一种需要先将图片按字符进行切割,这种方式比较数据处理比较复杂,而这种正是循环神经网络RNN要求的输入。
为了充分利用循环神经网络RNN处理序列数据的能力,同时避免对输入序列图像进行切分,本文作者提出了Connectionist Temporal Classificatio(CTC)算法。
# 2.Connectionist Temporal Classification(CTC)算法
# 2.1 什么是Temporal Classification
输入空间
Temporal Classification的任务是使用训练数据
从第一部分介绍,可以知道OCR任务本身就是一个Temporal Classification,翻译成了时间序列分类问题。其输入是卷积后得到特征图序列,输出的是字符序列。
之所以被称为Connectionist Temporal Classification,是这样理解的,原始输入的是一整张联结在一起未切分的字符图像,输出的是字符序列,因为没有对原始图像上的字符进行切分预处理,因此被称之为连接序列分类。
# 2.2 CTC问题描述
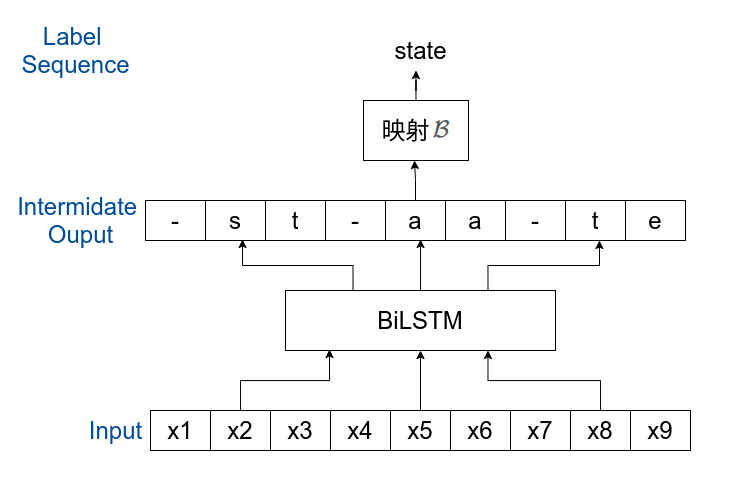
从网络输入到获取标签序列要分成两步:
第一步,可以将输入为长度为
根据以上定义给定输入
其实,这里还有个条件,就是每一步输出之间是相互独立,上面的公式才能成立。
第二步,我们知道输入
# 2.2关于对齐
为什么要使用上述的方法来进行网络的训练呢?那是因为输入

如上图是对齐后的数据,但在实际中是很难知道
# 2.3 前向后向算法
使用暴力方法计算
因为要计算每一条路径,因此对于序列字典中有
先借个例子来看一下。
假设标签序列为
在序列前后和每个字符中间添加空格占位符
对
将
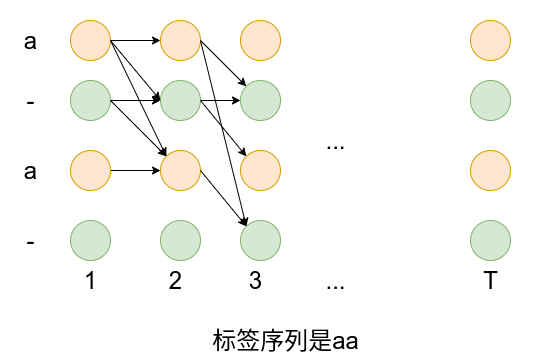
从上图可以看到,四条路径在序列
记
然后上面四条路径的概率和可以写成:
上面的介绍中只取了四条经过变换
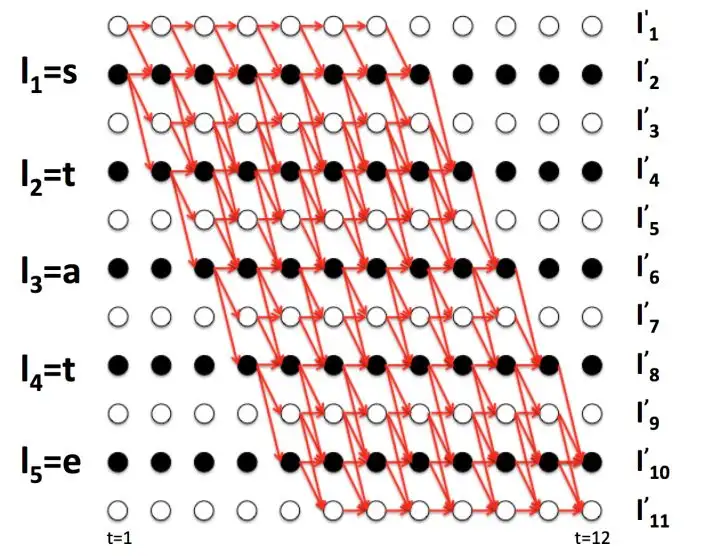
从上图中选出经过
进一步推广,定义
可以看到这等同于前向变量
还看
一般化推广可得:
还需考虑一个特殊情况,看下面例子
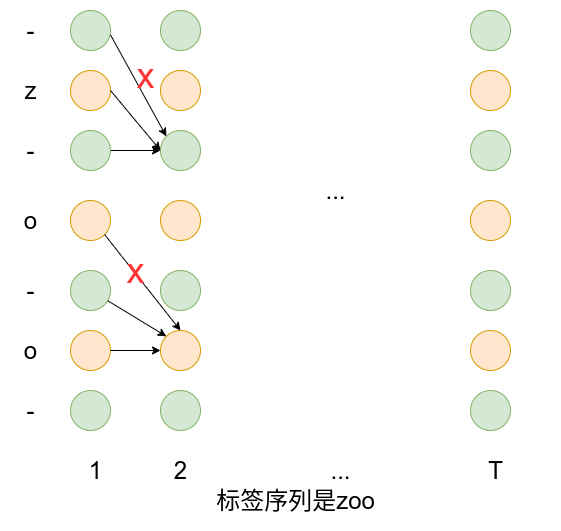
很明显因为
综上,可得最终
将公式中相同的项合并一下就可以得到论文上的公式了。
同样的方法可以定义
求得
求得
# 2.4 推理时
训练完成后,在网络推理时希望取概率最大的输出序列:
对所有路径的概率求和,然后取概率最大的路径作为预测的结果,应该是最合理的方式,但当序列比较长时面临计算量过大,影响推理速度的情况。
一种做法是对于第
一种替代的折衷方法是改进版的Beam Search。
常规的Beam Search算法,对于每个时间步取概率最大的几个(Beam Size)可能结果,如下为字母集为Beam Size=3的Beam Search的过程:

上图中Beam Search到当前步最大的几个(Beam Size)可能字符都只有一条前缀序列,实际上可以有多条前缀序列和当前的字符组合后都得到相同的输出,如下图对于路径长度
且观察
# 3.pytorch中的CTCLOSS
计算未切分的连续时间序列和目标序列之间的损失。 (opens new window)
torch.nn.CTCLoss(blank=0, reduction='mean', zero_infinity=False)
class CTCLoss:
...
def forward(self, log_probs: Tensor, targets: Tensor, input_lengths: Tensor, target_lengths: Tensor) -> Tensor:
...
log_probs:Tensor of size (T,N,C)/(T,C),T是输入长度,N是
Batch Size,C是序列字典的大小(包括空格)targets:Tensor of size(N,S)
N是batch size,S是最大目标序列长度,目标序列中的每个元素是类别的序号。input_lengths,每个输入序列的长度,为元组tuple或shape为(N,)的张量,N是batch size,input_lengths的值target_lengths,每个目标序列的长度,为元组tuple或shape为(N,)的张量,N是batch size,如果targets的shape是(N,S),这里其实是把每个padding后变成了S,假设第n个序列目标长度为target_lengths中第n个元素值就为
import torch
T = 2
C = 3
N = 1
S = 2
S_min = 1
input = torch.randn(T,N,C).log_softmax(2).detach().requires_grad_()
print(input)
target = torch.tensor([0,1], dtype=torch.long).reshape(shape=(N, S))
print(target)
input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long)
target_lengths = torch.tensor([2], dtype=torch.long).reshape(shape=(N,))
ctc_loss = torch.nn.CTCLoss()
loss = ctc_loss(input, target, input_lengths, target_lengths)
print(loss)
# tensor([[[-0.4002, -1.5314, -2.1752]], [[-0.8444, -2.2039, -0.7770]]], requires_grad=True)
# tensor([[0, 1]])
# tensor(1.3021, grad_fn=<MeanBackward0>)
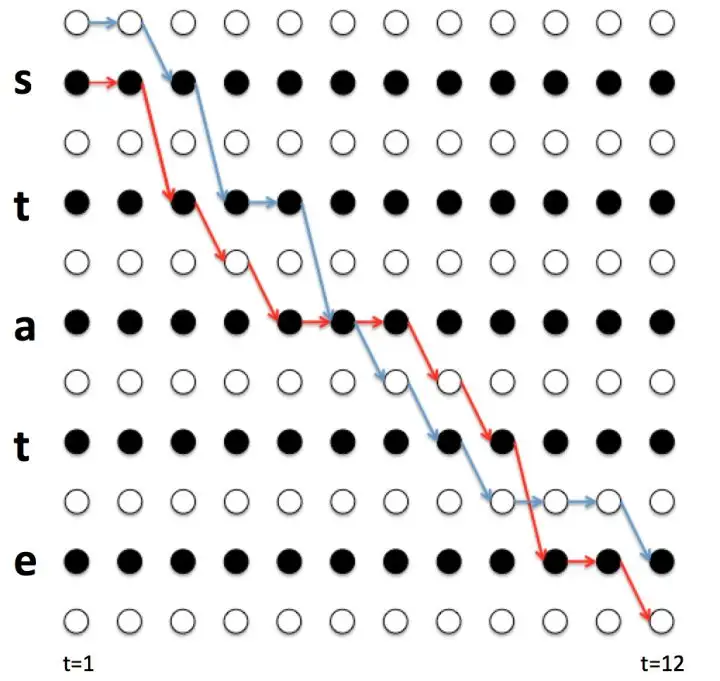
上面示例的计算过程:
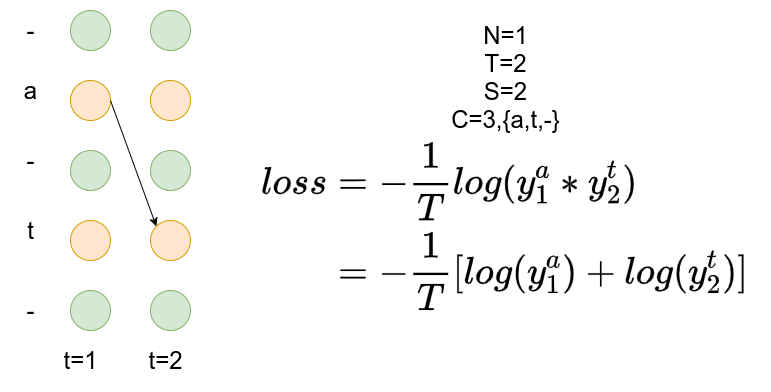
从上图可以看到目标是at路径有且仅有此一条,损失值计算为: