# 1.C++语言处理过程
编辑--> 预处理 --> 编译 --> 汇编 --> 链接
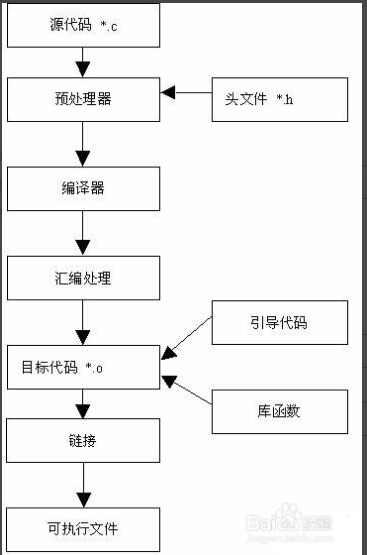
- 编辑: 编写源代码
- 预处理: 预处理阶断是对源码中的预处理代码进行处理。
// 预处理文件生成.i 文件
g++ -E test.c -o test.i
- 编译: 编译阶断是将源码处理为汇编代码
// 编译文件生成.s 文件
g++ -S test.i -o test.s
- 汇编: 汇编阶断是将汇编代码处理为二进制代码
// 汇编生成二进制.o文件
g++ -c test.s -o test.o
- 链接: 链接阶断将二进制代码打包成一个操作系统可以识别的可执行文件格式
// 链接生成可执行文件
g++ -c test.o -o test
预处理指令:
预处理指令不是C++语句,因此行尾不需要使用;,如需分行,使用反斜杠\进行分割,在预处理阶段将会进行语句替换。
# 2.1宏定义
#define和undef
#define MAX(a,b) ((a)>(b)?(a)\
:(b))
#undef MAX(a,b) // release the macro definition
#和##
# 后跟1个参数名称,在预处理阶段将被替换成被两个双引号包起来的字符串常量形式。
#define str(x) #x
cout << str(test_test) << endl;
str(test_test)将在预处理阶段被替换成"test_test"
## 是在预处理阶段连接两个参数,中间无空格且不带“”,连接的结果会被直接作为C++中的语句。
#define glue(a,b) a ## b
glue(c,out) << "test";
# 2.2条件包含指令
#ifdef
#ifndef
#if
#elif
#else
#endif
#ifdef,#ifndef,条件编译一段代码,与endif一起使用,判断宏是否有定义,并不关心其值
#ifdef N
int a[N];
#endif
定义了N就定义数组a,未定义N就不定义数组a。#ifndef判断如果未定义某个宏就执行其中语句。头文件中经常会加上此句,防止重复引入.h文件导致,重复定义。
#ifndef HEADER_H
#define HEADER_H
#endif
#if,else,elif 根据宏的不同的值,执行不同的操作
#if TABLE_SIZE>200
#undef TABLE_SIZE
#define TABLE_SIZE 200
#elif TABLE_SIZE>100
#undef TABLE_SIZE
#define TABLE_SIZE 100
#else TABLE_SIZE>50
#undef TABLE_SIZE
#define TABLE_SIZE 100
#endif
# 2.3 #error指令
#error抛出编译过程中检查出来的错误信息, 打印的是其后的参数
#ifndef __cplusplus
#error A C++ compiler is required!
#endif
# 2.4 行控制
#line指令,当某行编译过程中出现异常时,定制打印错误信息
行号就是#line指令指定的那一行,编译器会预处理的过程会自动处理。
42 #line 43 "declaration variable"
43 double num+;
# 2.5 源码包含
预处理器在碰到#include指令时,会使用include的文件进行源码替换
头文件中经常会加上此句,防止重复引入.h文件导致,重复定义。
#ifndef HEADER_H
#define HEADER_H
#endif
两种包含方式的区别:
- 1.使用
#include <>包含头文件时,系统会到默认目录(编译器和环境变量等所定义的头文件目录)查找要包含的文件,这是标准方式; - 2.使用
#include ""包含头文件时, 系统会先到用户当前目录(即项目目录)中查找要包含的文件,查找不到会将""替换成<>再按标准方式查找;
#include <header>
#include "file"
# 2.6 #pragma指令
#pragma 指令和平台和所使用的编译器强相关,不同的平台提供不同的#pragma操作。
常用的#pragma once,防止某个头文件被多次include,#ifndef,#define,#endif用来防止某个宏被多次定义。
#pragma once是编译相关,就是说这个编译系统上能用,但在其他编译系统不一定可以,也就是说移植性差,不过现在基本上已经是每个编译器都有这个定义了。#ifndef,#define,#endif这个是C++语言相关,这是C++语言中的宏定义,通过宏定义避免文件多次编译。所以在所有支持C++语言的编译器上都是有效的,如果写的程序要跨平台,最好使用这种方式
#pragma message("消息文本")
// 比较常用的指令,只要在头文件的最开始加入这条指令就能够保证头文件被编译一次
#pragma once
...
# 2.7 C++中预定的宏
一定有的宏:
| 名称 | 描述 |
|---|---|
__LINE__ | 编译时当前行的行号 |
__FILE__ | 源文件名称 |
__DATE__ | 编译开始的日期,形如mm dd yyyy,例:Apr 11 2021 |
__TIME__ | 编译开始的时间,形如hh:mm:ss,例:18:15:47 |
__cplusplus | 整数值,取决于C++编译器支持的标准,如:201402 |
__STDC_HOSTED__ | C++11新增预定义的宏,宿主环境是否具有标准C库的完整功能,如果具有标准C库的完整功能则__STDC_HOSTED__定义为1,否为定义为0 |
可选的宏:
| 名称 | 描述 |
|---|---|
__STDC__ | 指示编译器是否支持ISO标准C语言,如果支持ISO标准C语言则_STDC__定义为1,否为定义为0,甚至有些编译器未定义 |
__STDC_VERSION__ | 用于定义C标准的版本号,但是标准文档中并没有明确规定其实现,所以在很多编译器中这个宏处于未定义状态 |
__STDC_MB_MIGHT_NEQ_WC__ | |
__STDC_ISO_10646__ | 用于指示wchar_t是否使用Unicode,如果使用Unicode那么wchar_t展开为yyyymmL的形式 |
__STDCPP_STRICT_POINTER_SAFETY__ | 如果实现中有strict pointer safety (opens new window)返回1 |
__STDCPP_THREADS__ | 如果程序可以有多线程,则为1 |
# 参考资料
← C++编译器 C++预处理及宏定义 →