论文: https://arxiv.org/abs/1805.06725
代码: https://github.com/samet-akcay/ganomaly
# 1.介绍
GANomaly是英国杜伦大学(Durham University,QS前100)Samet Akcay等发表在ACCV2018上的会议论文。
这篇文章是期望提出一种可以只在正常数据上训练,但却能识别异常图像的方法。其提出了由对抗训练框架组成的通用异常检测模型。本文作者在编码-解码-编码式的架构中使用了对抗自编码器,获取训练数据在图像和隐式向量中的分布。
这篇文章主要贡献:
半监督异常检测,提出了基于编码-解码再编码架构的对抗式自编码器,获取训练数据在图像和隐式向量空间的分布,取得比其他基于GAN网络和自编码器异常检测方法更好的效果
代码开源
# 2.GANomaly网络组成
# 2.1 GAN简介
生成对抗网络Generative Adversarial Networks (GAN)是蒙特利尔大学Université de Montréal的Ian Goodfellow 2014年发表的论文(作者Ian Goodfellow最近因不让居家办公了从Apple公司离职媒体正宣传的热闹),GAN属于无监督机器学习算法,原来GAN模型的目标是为了生成原始数据, 其结构包括在训练过程中对抗的两部分,生成器和对抗器,生成器负责生成与source data尽可能相似的数据,判别器负责尽可能的找出生成器生成的fake data。关于GAN的更多介绍可参考:(一)深度卷积对抗网络DCGAN (opens new window)
# 2.2 问题定义
异常检测问题的正式定义:
- 数据集,训练数据集
- 目标模型学习数据
# 2.3网络结构
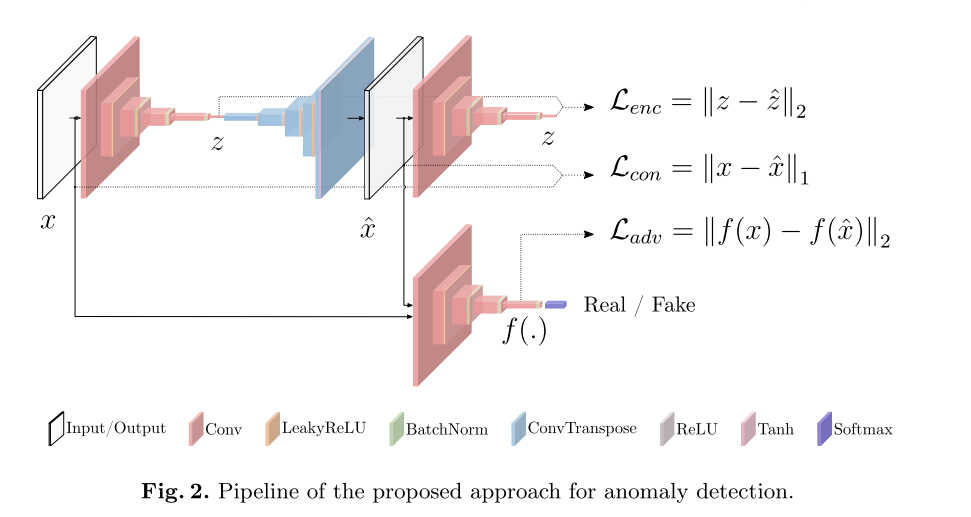
网络结构如上图,GANormaly主要包括3部分,以个自编码器,一个编码器和一个生成器。第一部分是一个蝴蝶结形的自编码网络作为模型的生成器,生成器学习输入数据表征,通过编码和解码网络重建输入数据。生成器中编码网络的输出GANomaly通过增加一个编码网络,显式的学习最小化特征距离。第3部分是判别器网路D,其目标是判别输入real还是fake。
# 3.模型训练
因训练时只使用了正常类别的数据,可以假设即使生成器的编码器可以将输入数据
GANomaly模型包含
# 3.1对抗损失
Adversarial Loss
其使用的是特征对齐的损失函数,而非基于判别器输出,
上式中
# 3.2 上下文损失
Contextual Loss
为了学习输入数据中的上下文信息,增加衡量输出数据
# 3.3 编码器损失
Encoder Loss,前面两个损失函数不仅可以让生成的数据尽量真实,还能保存数据的上下文信息。引入Encoder Loss是为了使
最终,GANomaly的损失函数为:
# 4.模型测试
测试阶段模型使用
为了评估整体的异常性能,对测试数据集
# 5.代码分析
GANomaly的代码基于pytorch实现,代码使用方法说明的很清晰。
# 5.1数据加载
GANomaly数据加载使用的torchvision提供的ImageFolder类,只需按
Custom Dataset
├── test
│ ├── 0.normal
│ │ └── normal_tst_img_0.png
│ │ └── normal_tst_img_1.png
│ │ ...
│ │ └── normal_tst_img_n.png
│ ├── 1.abnormal
│ │ └── abnormal_tst_img_0.png
│ │ └── abnormal_tst_img_1.png
│ │ ...
│ │ └── abnormal_tst_img_m.png
├── train
│ ├── 0.normal
│ │ └── normal_tst_img_0.png
│ │ └── normal_tst_img_1.png
│ │ ...
│ │ └── normal_tst_img_t.png
这样的格式将数据存放好即可。
"""
加载自定义数据的代码
"""
splits = ['train', 'test']
drop_last_batch = {'train': True, 'test': False}
shuffle = {'train': True, 'test': True}
transform = transforms.Compose([transforms.Resize(opt.isize),
transforms.CenterCrop(opt.isize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ])
dataset = {x: ImageFolder(os.path.join(opt.dataroot, x), transform) for x in splits}
dataloader = {x: torch.utils.data.DataLoader(dataset=dataset[x],
batch_size=opt.batchsize,
shuffle=shuffle[x],
num_workers=int(opt.workers),
drop_last=drop_last_batch[x],
worker_init_fn=(None if opt.manualseed == -1
else lambda x: np.random.seed(opt.manualseed)))
for x in splits}
return dataloader
# 5.2 损失定义
""" Backpropagate through netG
"""
self.err_g_adv = self.l_adv(self.netd(self.input)[1], self.netd(self.fake)[1])
self.err_g_con = self.l_con(self.fake, self.input)
self.err_g_enc = self.l_enc(self.latent_o, self.latent_i)
self.err_g = self.err_g_adv * self.opt.w_adv + \
self.err_g_con * self.opt.w_con + \
self.err_g_enc * self.opt.w_enc
self.err_g.backward(retain_graph=True)
损失函数的使用如上述代码。
# 6.测试效果
- 数据量
| Nomaly | Abnomaly | |
|---|---|---|
| TES | 290 | 747 |
| TRAIN | 291 |
- 测试结果
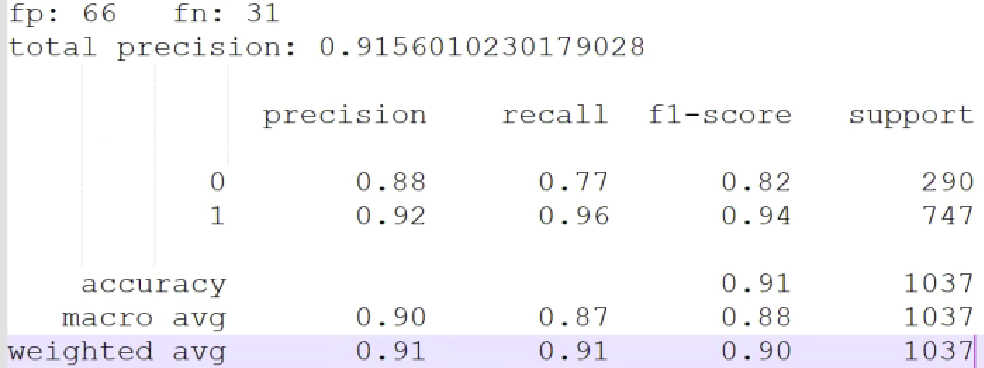
- 可以看到准确率只有91%,效果在自定义的数据集上还不太好,不容易应用
注,上图分类评估指标可参考(二)sklearn.metrics.classification_report中的Micro/Macro/Weighted Average指标 (opens new window)求得。
# 参考资料
← 生成对抗网络