# Mask R-CNN in Detectron2 for Key Point Detect
# 1.COCO数据集中定义的人体关键点检测任务

人体关键点检测常用于人体姿态估计,不仅需要找到人的bounding box,还需要找出其中关键点的位置。coco中human这个类别每个对象定义了17种关键点,依次是['nose', 'left_eye', 'right_eye', 'left_ear', 'right_ear', 'left_shoulder', 'right_shoulder', 'left_elbow', 'right_elbow', 'left_wrist', 'right_wrist', 'left_hip', 'right_hip', 'left_knee', 'right_knee', 'left_ankle', 'right_ankle'],此外还有skeleton骨架字段,表示各个种类关键点之间的连接信息,如[6, 7]表示left_shoulder与left_elbow相连。具体的关系如下:
{
1: {
'supercategory': 'person',
'id': 1,
'name': 'person',
'keypoints': ['nose', 'left_eye', 'right_eye', 'left_ear', 'right_ear', 'left_shoulder', 'right_shoulder', 'left_elbow', 'right_elbow', 'left_wrist', 'right_wrist', 'left_hip', 'right_hip', 'left_knee', 'right_knee', 'left_ankle', 'right_ankle'],
'skeleton': [
[16, 14],
[14, 12],
[17, 15],
[15, 13],
[12, 13],
[6, 12],
[7, 13],
[6, 7],
[6, 8],
[7, 9],
[8, 10],
[9, 11],
[2, 3],
[1, 2],
[1, 3],
[2, 4],
[3, 5],
[4, 6],
[5, 7]
]
}
}
在coco的标注文件中,keypoints检测数据集的标注信息类别如以上介绍的17种,另外在annotation中增加了num_keypoints和keypoints字段,分别表示当前实例中包含了几个关键点和关键点的具体位置信息。keypoints是长度为3k的数组,其中k是关键点的类别数目,coco中k=17,3表示的是关键点的(x,y,v),x,y是关键点在原图上的坐标,v取0,1,2,定义的是关键点是否可见,其中v=0表示关键点没有标注,表示为(x=0,y=0,v=0),v=1表示标注但被遮挡,v=2表示标注且可见。
coco中只标注了图像中非拥挤场景中级以上大小的human的keypoints,训练/验证/测试数据包括超过200000张图像,250000个人体图像标注了关键点,训练/验证数据中有超过150000个人体图像,标注了超过1 700 000个关键点,keypoints标注文件的字段如下 (opens new window):
annotations[{
"id": int,
"image_id": int,
"category_id": int,
"segmentation": RLE or [polygon],
"area": float,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1,
"keypoints": [x1,y1,v1,...],
"num_keypoints": int
}]
categories[{
"id": int,
"name": str,
"supercategory": str,
"keypoints": [str],
"skeleton": [edge],
}]
# 2.Detectron2中实现的Mask R-CNN用于Keypoints关键点检测
前面介绍了RPN和RoI Pooler,通过RPN (opens new window)网络可以找到可能包含物体的proposal bounding boxes,RoI Pooler (opens new window)可以对proposal bounding boxes的选定区域进行特征提取,以这两个技术为基础,Mask R-CNN可用来实例分割和关键点检测。
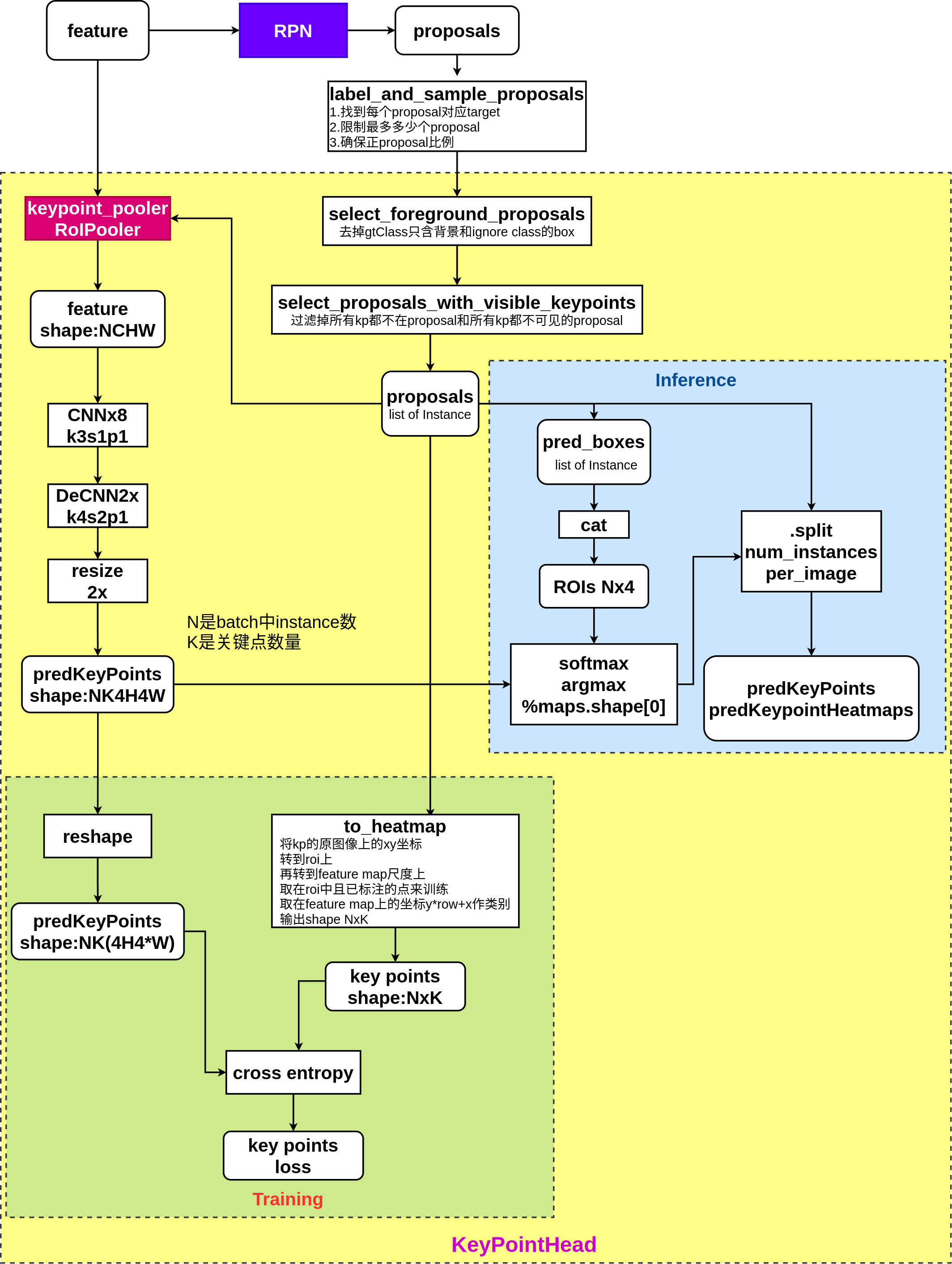
Mask R-CNN中实现的key points检测如上图所示,使用的是heatmap概率图的方式,keypoint_head是roi_head中的一个分支,其输入的features是对backbone提取的图像特征features做RoI Pooler后得到的, 输入keypoint_head中的proposals已经没有了层级信息,在做RoI Pooler时有一个assign_boxes_to_levels的过程,其原理参考FPN (opens new window)论文中的方程1。 keypoint_head的结构如上图,由8个CNN组成,后跟1个Transposed CNN和1个向上2x的interpolation操作,用来输出key points heatmap prediction。若输入keypoint_head的feature shape为NxCxHxW,则输出feature shape为NxKx(4*H)x(4*W),其中K表示的是实例中定义的key point总的类别,N表示的是batch中所有的instance个数,其和图片的对应关系,保存在keypoint_head的另一个输入instances中。
keypoint_head的最终预测输出kp_heatmap pred是NxKx(4*H)x(4*W)的特征图,在训练时,根据gt_keypoints将其先转到(4*H)x(4*W)尺度上得坐标(x,y),再取y*kp_heatmap pred.cols+x作为此点的目标值,在K个通道取有效点与kp_heatmap pred上对应valid通道的(4*H)x(4*W)概率图计算交叉熵损失函数cross_entropy。其原理是对每个(4*H)x(4*W)的概率图上的元素做分类,target就是当前类别keypoint在heatmap尺度上的位置。推理时,对每个instance的K通道(4*H)x(4*W)的heatmaps,在每个通道heatmap上做softmax,求得概率最大的元素位置,即对应通道上keypoint的位置和评分,如此得到N个实例在K种关键点上预测的结果,NxKx(x,y,score)。最后,可以根据score的大小过滤掉K个通道上评分比较低的点。